





查看
动画化穿衣人物
(
另外,每种类型的变形(软组织或衣服)都需要不同的模型公式。然后,为了训练模型,3D/4D扫描需要与之对应,而这是一项具有挑战性的任务,尤其是对于服装。最近的研究利用隐式函数表示从图像或三维点云重建人体形状。但是,所述重建都为静态,不可设置动画。
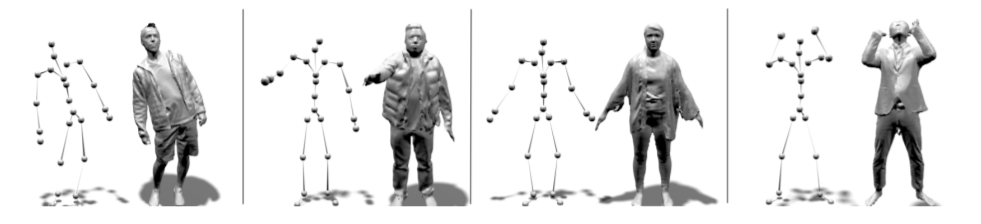
在名为《Neural-GIF:NeuralGeneralizedImplicitFunctionsforAnimatingPeopleinClothing》的论文中,图宾根大学、马克斯-普朗克研究所和
给定一个姿势(θ)作为输入,Neural-GIF可以预测SDF。为了训练Neural-GIF,团队需要对固定衣服中的被试进行3D扫描序列,以及需要相应的SMPL参数。研究人员将运动分解,以在角色的正则空间中学习可变形SDF。为了获得姿态相关SDK,团队合成了三个神经函数组成:
正则映射网络:通过学习的点与人体关联来将构成的三维空间中的每个点映射到正则空间;
位移场网络:为非刚性姿势相关变形(软组织、布料动力学)建模。具体来说,它预测了正则空间中点的连续位移场。
正则SDK:通过组合,正则SDF网络将上述网络中的变换点和姿态编码作为输入,以预测每个查询点所需的符号距离。团队同时预测了一个曲面法向场作为正则空间中姿势的函数,以增加结果的真实性。
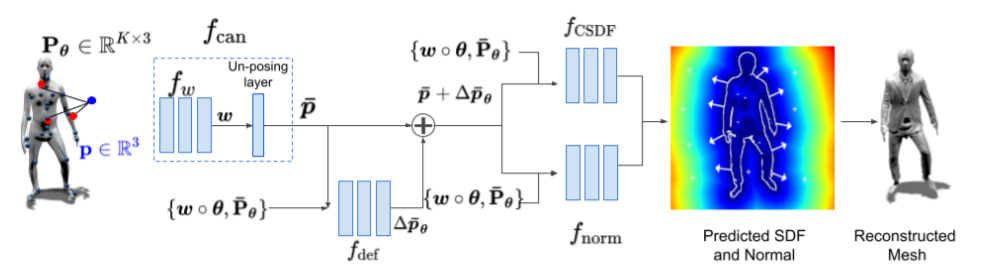
总的来说,Neural-GIF由一个神经网络组成,用于近似设定曲面的符号距离场(SDF)。原生学习从姿势预测SDF非常困难。相反,团队从基于模板的方法中得到启发,除了将运动分解为铰接和非刚性变形,同时将此概念泛化到内隐形状学习。具体地说,模型学习将曲面周围的每个点映射到正则空间。在这个空间中,系统在评估SDF之前会将学习到的变形场应用于非刚性效果的建模。Neural-GIF的优点是,网络可以更容易地在正则空间中学习基础形状。
团队在来自不同数据集的各种扫描上测试了所述方法,并提供广泛的定量和定性比较。研究人员同时通过添加形状相关的位移场网络,将公式扩展到多形状设置。实验表明,这一方法可以泛化到新的姿势,模拟复杂的服装,并且比现有的方法更加稳健和详细。
Neural-GIF:NeuralGeneralizedImplicitFunctionsforAnimatingPeopleinClothing
研究人员表示,Neural-GIF可以精确地建模任意拓扑和分辨率的复杂几何体,因为模型不需要预定义的模板,同时不需要对模板进行非刚性的扫描注册。它在鲁棒性、模拟复杂服装风格的能力和保留精细姿势相关细节方面比之前的研究有了显著的改进。团队相信NeuralGeneralizedImplicitFunctions开辟了几个有趣的研究方向,并计划在接下来的时间里进行探索。








