





查看
利用GPT-4V建立一个可定制、可扩展和与人类判断一致的评估指标
(映维网资讯)文生图(TexttoImage),文生视频(TexttoVideo)和文生3D(Textto3D)等领域正在蓬勃发展。可以想象,所述的文生技术可以与XR结合,为XR快速生成各种逼真场景。
但技术的发展初期可能存在缺乏可靠评估指标的问题。在围绕文生3D的研究中,由香港中文大学、斯坦福大学、

在神经三维表示,广泛数据集发展,可扩展生成式模式,以及用于3D生成的文本-图像基础模型的创新应用等一系列突破推动下,文生3D领域在过去的一年中取得了显著的进展。考虑到这一势头,我们有理由预计文生3D生成模型领域的研究工作和进展将迅速增加。
但团队认为,用于文生3D模型的适当评估指标并没有跟上步伐,而这一缺陷可能会阻碍进一步改进相关的生成式模型。他们指出,现有指标通常侧重于单一标准,缺乏多种3D评估需求的通用性。例如,基于Clip的指标旨在衡量3Dasset与其输入文本对齐的程度,但它们可能无法充分评估几何和纹理细节。这种灵活性的缺乏导致在评估标准中与人类的判断不一致。因此,许多研究人员依靠用户研究来进行准确和全面的评估。
另一方面,尽管用户研究具有适应性,可以准确地反映人类的判断,但它们可能成本高昂,难以扩展,而且耗时。所以,大多数用户研究都是围绕一组非常有限的文本提示输入进行。
这就引出了一个问题:我们能否创建自动度量标准,使其适用于各种评估标准,并与人类的判断紧密结合?
设计满足标准的度量标准涉及三个基本功能:生成输入文本提示、理解人类意图以及对3D物理世界的推理。幸运的是,LMMs,特别是GPT-4
团队从人类在语言指导下使用2D视觉信息执行3D推理任务的能力中获得灵感,并假设GPT-4V能够执行类似的3D模型评估任务。
在名为《GPT-4V(ision)isaHuman-AlignedEvaluatorforText-to-3DGeneration》中,研究人员提出了一个概念验证,展示了使用GPT-4V为文生3D任务开发可定制的、可扩展的、与人类一致的评估指标。
构建这样一个评估度量类似于创建一次考试,它需要两个步骤:制定问题和评估答案。为了有效地评估文生3D模型,获得一组准确反映评估者需求的输入提示至关重要。
依靠静态的、启发式生成提示并不足够。相反,研究人员开发了一个“meta-prompt/元提示”系统,其中GPT-4V根据评估重点生成一套量身定制的输入提示。在生成相关输入文本提示之后,所述方法涉及将3D形状与用户定义的标准进行比较,类似于在考试中评分。
为文生3D模型创建评估指标需要决定应该使用哪组输入文本提示作为模型的输入。理想情况下,我们希望使用所有可能的用户输入提示,但这对计算而言不可行。或者说,我们希望构建一个能够输出模拟用户输入的实际分布的提示的生成器。
评估指标的目标是根据用户定义的标准对一组文生3D模型进行排名。团队提出的方法涉及两个主要组件。首先,需要决定使用哪个文本提示符作为评估任务的输入。为了实现这一目标,研究人员开发了一个自动提示生成器,它能够生成具有可定制复杂性和创造力水平的文本提示。第二个组件是一个多功能3Dasset比较器,它根据输入评估标准比较由给定文本提示生成的一对3D形状。
总之,所述组件允许团队使用Elo评级系统为每个模型分配一个排名分数。
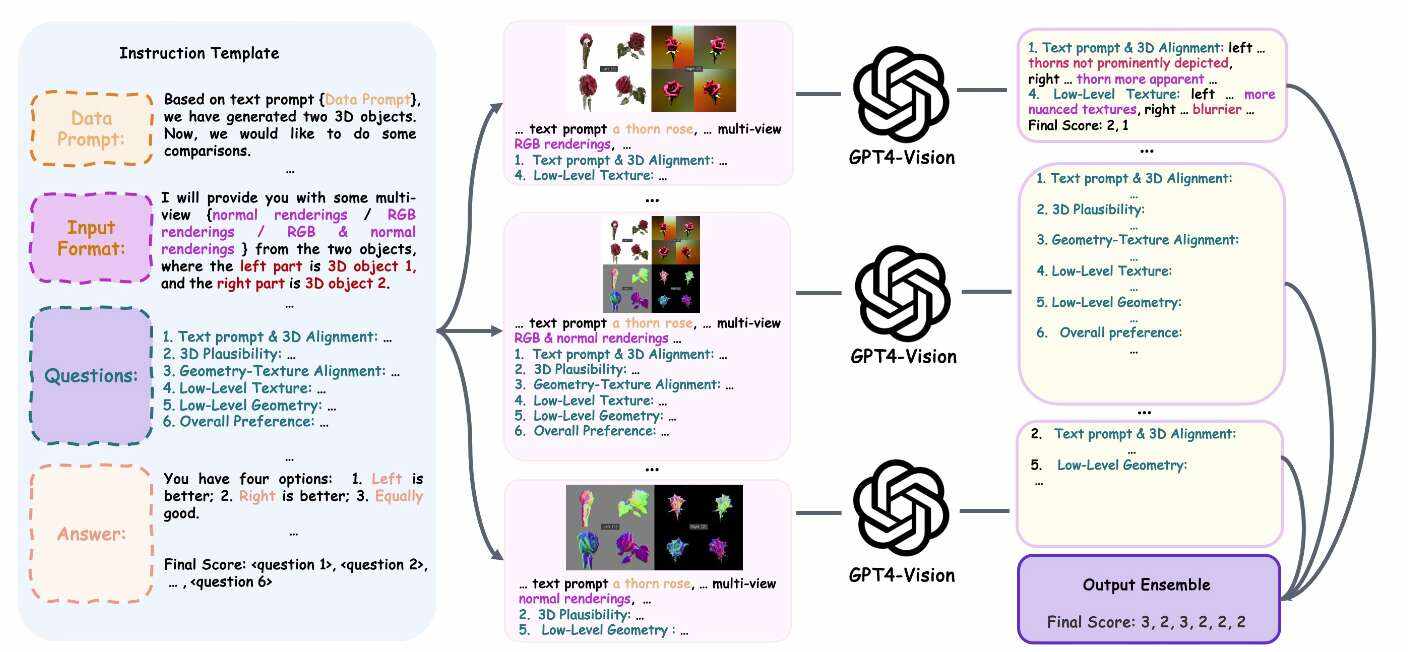
如上图所示,团队创建了一个可定制的指令模板,其中包含GPT-4V进行两个3Dasset比较任务所需的信息。研究人员用不同的评估标准完成这个模板,输入3D图像和随机种子,为GPT-4V创建最终的3D感知提示。然后,GPT-4V将消耗相关输入以输出其评估。最后,他们收集了GPT-4V的答案,以创建对任务的可靠最终估计。
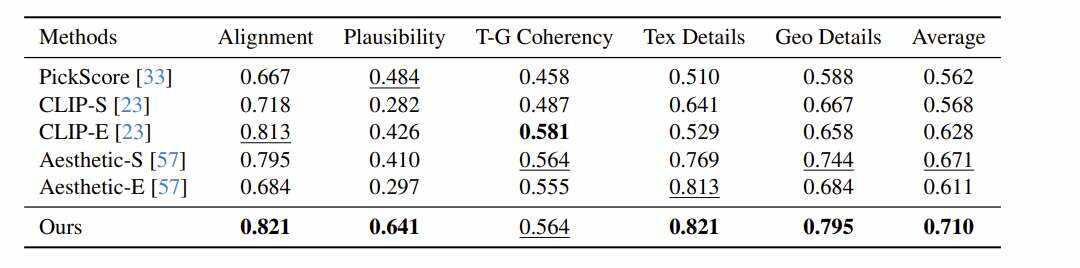
初步的经验证据表明,团队提出的框架可以超越现有的指标,在不同的评估标准中实现与人类判断更好的一致性。结果表明,相关度量可以有效地提供针对文生3D模型的高效和全面评估。

不过,团队坦诚自己的方案依然面临数个尚未解决的挑战:
由于资源有限,论文的实验和用户研究规模相对较小。扩大研究规模对于更好地验证假设非常重要。
GPT-4V的响应并不总是正确。例如,GPT-4V有时会出现幻觉,这是许多大型预训练模型普遍存在的问题。
一个好的指标应该是“不可欺骗的”。然而,人们可能会构建对抗模式来攻击GPT-4V。这样,人们可能在不需要生成高质量3Dasset的情况下获得高分。
尽管论文的方法比进行用户偏好研究更具可扩展性,但可能会受到计算限制,例如GPT-4VAPI访问限制。随着要评估的模型数量的增长,论文的方法需要四次方增长的比较次数,这在计算资源有限的情况下可能无法很好地扩展。所以,研究如何利用GPT-4V智能选择输入提示来提高效率将非常有趣。
GPT-4V(ision)isaHuman-AlignedEvaluatorforText-to-3DGeneration
总的来说,论文提出了一个利用GPT-4V的新框架,以为文生3D任务建立一个可定制的、可扩展的、与人类判断一致的评估指标。首先,团队提出一个提示生成器,它可以根据评估者的需要生成输入提示。其次,他们用一系列可定制的“3D感知提示”来提示GPT-4V,使得GPT-4V能够根据评估人员的需要对两个3Dasset进行比较,同时保持与各种标准的人类判断一致。
有了这两个组件,研究人员就可以使用Elo系统对文生3D模型进行排序。实验结果证实,团队提出的方法可以在各种标准中优于现有的度量。







