





查看
自中心手部姿态数据集
(
在这种场景中,用户通过双手操纵对象是一种非常重要的交互方式。特别是,手的姿态在理解和实现手-物交互、基于姿态的动作识别和交互界面中起着核心作用。社区已经提出了数个用于理解自中心活动的大规模数据集,如EPICKITCHENS、Ego4D和Assembly101。特别是,Assembly101强调了3D手在识别程序性活动的重要性,例如组装玩具。
值得注意的是,Assembly101的作者发现,对于组装动作的分类,从3D手部姿态中学习比仅仅使用视频特征更有效。然而,所述研究的一个缺点是,Assembly101中的3D手部姿态注释并不总是准确,因为它们是从现成的自中心手部追踪器计算出来的。如图1可以观察到,提供的姿态往往是不准确,特别是当手被物体遮挡时。
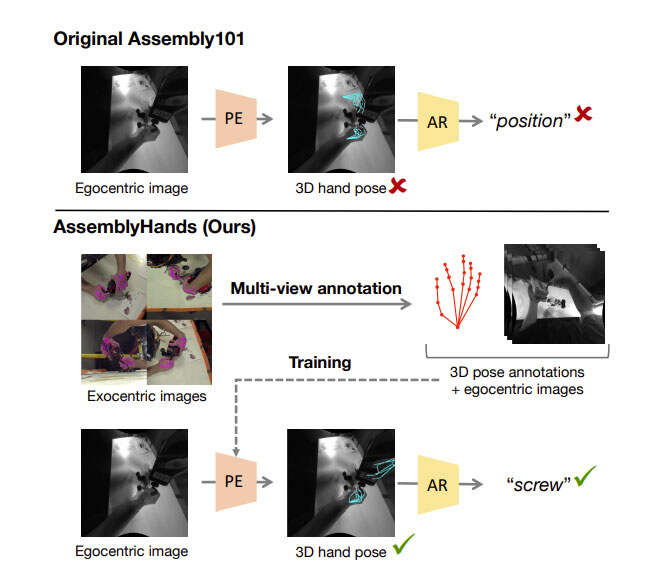
因此,之前的研究给社区留下了一个未解决的问题:3D手部姿态的质量如何影响动作识别性能?
为了系统地回答这个问题,由Meta和东京大学的研究人员提出了一个名为AssemblyHands的新基准数据集。它包括从Assembly101采样的总共3.0M图像,并使用高质量的3D手部姿态注释。他们不仅获得了手动标注,而且利用它们来训练精确的自动标注模型,通过第三人称图像的多视图特征融合。

如图2所示。模型实现了4.20mm的平均关键点误差,比Assembly101中提供的原始注释低85%。这种自动管道使得能够有效地将注释扩展到来自34个主题的490K以自中心图像,令AssemblyHands成为迄今为止最大的自中心手部姿态数据集,包括规模和主题多样性方面。
与DexYCB和H2O等手-物姿态数据集相比,AssemblyHands具有明显更多的手-物组合。鉴于标注的数据集,他们首先使用2.5Dheatmapoptimization和handidentityclassification开发了一个强大的基线,以用于自中心3D手姿态估计。然后,为了评估手部姿态预测的有效性,团队提出了一种新的评估方案:手部姿态的动作分类。与先前的自中心手部姿态估计基准不同,他们详细分析了3D手部姿态注释的质量,其对自中心姿态估计器性能的影响,以及预测姿态在动作分类中的应用。
AssemblyHands数据集生成
所述基准测试中的输入数据来自Assembly101。尽管它可以以合理的精度估计3D手部姿态,但存在数个限制。例如,由于自为中心摄像头的立体区域相对狭窄,当手远离图像中心时,深度估计就会变得不准确。
另外,在手物交互过程中,由于严重的遮挡,仅自中心追踪容易出现严重的故障模式。这促使团队开发一种使用非自中心(第三人称视角)RGB摄像头的多视图注释方法。尽管存在现有的数据集使用基于RGB的模型来注释手部姿态(例如OpenPose),但它们在Assembly101中的准确性并不令人满意。由于OpenPose是在较少手物遮挡图像进行训练的,因此当在Assembly101中呈现新颖现实世界对象和更高水平的遮挡时,其预测通常充满噪点。
因此,有必要开发一种适合新设置的注释方法。
团队在名为《AssemblyHands:TowardsEgocentricActivityUnderstandingvia3DHandPoseEstimation》的论文中提出了一种基于多视图第三人称RGB图像的自动标注管道。首先为从Assembly101的子集中以1hz采样的帧准备手动注释。由于获取手工标注非常费力,研究人员使用它们来训练一个标注网络,从而自动提供合理的3D手部姿态标注。
然后,他们详细介绍了相关的标注网络:
- 使用MVExoNet的标注网络;
- 在网络推理过程中进行迭代改进。
与手动标注相比,这种自动标注方案允许他们在30Hz采样的Assembly101的另一个子集中分配21倍的标签。
首先,获得了双手21个关节在世界坐标空间中的三维位置的手工标注。总的来说,他们以1Hz的采样率注释了来自Assembly101的62个视频序列,并得到了一组22K帧的注释集,每个帧有8个RGB视图。
研究人员进一步将其分成54个序列用于训练,8个序列用于测试Volumetric标注网络。接下来,设计了一个三维关键点标注的神经网络模型。对于多摄像投设置,标准方法是对2D关键点检测进行三角测量,他们称之为“2D+三角测量”基线。例如,在InterHand2.6M中,由于摄像头数量较多(80到140个),这种方法可以达到2.78mm的精度。但对于Assembly101,在8台RGB摄像头这种数量有限的情况下,2D+三角测量只能达到7.97mm(见表2)。
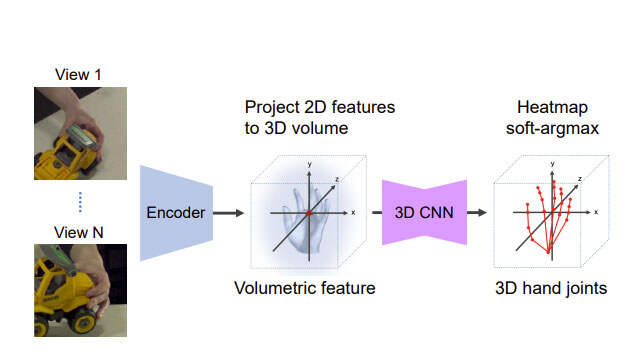
另一方面,端到端的“可学习三角测量”方法在人体姿态估计方面优于标准三角测量。因此,团队采用这一原理,设计了一个基于三维体特征聚合的多视角手部姿态估计网络。他们将体积网络命名为MVExoNet,并在图3中展示其设计。
首先,特征编码器为每个视图提取2D关键点特征。然后,使用基于softmax的加权平均值将特征投影到单个3D体中。然后,基于三维卷积的编码器-解码器网络细化体积特征并输出3D热图。在热图上采用soft-argmax运算获得三维关节坐标。
对于架构,使用effentnet作为编码器,在体积聚合之前提取紧凑的2D特征,以节省GPU内存。他们使用V2VPoseNet作为三维卷积网络。在训练期间,通过稍微扩展包含手动注释的2D关键点的区域来生成2D手动裁剪。三维体每侧长300mm,以中指底部为中心(即第三个MCP关节)。
团队同时通过在每个轴上添加随机噪点来增加体积的根位置,这可以防止模型总是将体积的源预测为第三个MCP。在测试时,根据手部检测器的输出裁剪手部区域,并使用2D+三角测量基线预测的第三个MCP作为体积根。然后,他们在MVExoNet的推理过程中提出了一种简单的迭代改进启发式方法。
如上所述,MVExoNet需要手动boundingbox来裁剪输入图像,并需要根位置来构建3D体。在测试时,boundingbox和体积根分别来自于初始2D关键点预测的手检测器和三角测量,并可能存在不准确性。
迭代改进是由以下观察结果驱动的:由于MVExoNet已经生成了合理的预测,可以使用它的输出来重新初始化手部作物和体积根位置。这使得网络在每个连续的回合中都有更好的输入。
他们将原始模型命名为MVExoNet-R1,将接下来的几轮命名为MVExoNet-R2,以此类推。在每一个额外的回合中,根据mvexonein在前一轮中生成的投影2D关键点定义输入手部裁剪,并将3D体集中在预测的根位置上。注意,在迭代精化推理期间冻结了MVExoNet,并且只更新模型的输入(即boundingbox和体积根)。
评估
接下来,将提出的注释方法的准确性与几个基线进行比较,包括原始Assembly101中使用的自中心手部追踪器。
首先,为了评估分布内泛化,使用了来自Assembly101的手动注释测试集,其中包含从8个序列中以1hz采样的帧。他们同时考虑了对不可见多摄像头设置的泛化。为此,使用最近发布的AriaPilotDataset中的DesktopActivities子集。
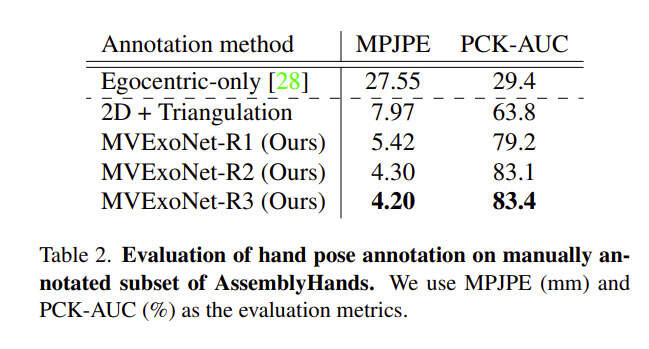
表2比较了手动标注的评估集上标注方法的准确性。Assembly101中的原始手部注释是由一个以自中心的手部姿态估计器UmeTrack计算的,使用的是自中心摄像头的单色图像。自中心标注的误差为27.55mm,明显高于使用2D+三角剖分和团队提出的方法。
研究人员发现,当手持物体阻挡了用户的视角时,自中心摄像头的注释变得不准确。对于这种情况,来自多个第三视角摄像头的关键点预测有助于定位被遮挡的关键点。通过融合来自多视角图像的体积特征,MVExoNet比标准的2D+三角测量基线性能要好得多。
如表2所示,初始推理结果(MVExoNet-R1)达到了合理的性能,误差为5.42mm。经过两轮迭代改进,进一步将标注误差从5.42mm减少到4.20mm(减少22.5%)。

图4可视化了手部裁剪和MVExoNet在Assembly101和DesktopActivities的预测的转换。第一轮的手部裁剪对两个数据集来说都不是最优的。例如,模型无法区分要标注哪只手,因为两只手都位于Assembly101(左)中的图像中心。另外,这只手在图像上方(右上)移动,看起来很小(右下)。考虑到这种次优手部裁剪,预测变得充满噪点,
但在之后的回合中,手部裁剪逐渐聚焦于目标手(例如左上角的左手),这提高了关键点的定位。
为了评估团队注释方法的跨数据集泛化能力,他们使用了DesktopActivities。其中,所述数据集同时具有多摄像头设置中的手-物交互功能。
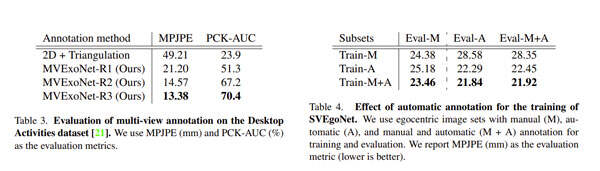
如表3所示,由于新的摄像头配置和新对象的存在,所有方法获得的误差都高于Assembly101设置。特别是,基线注释方法2D+三角测量在应用于DesktopActivities时显著降低,MPJPE接近50mm。相比之下,MVExoNet在新设置下非常稳健,初始MPJPE为21.20mm,经过两轮迭代优化后达到13.38mm(误差降低36.9%)。
结果
表4分别比较了在手动(M)、自动(A)和手动+自动注释(M+A)的数据集训练的SVEgoNet的性能。他们提供了Eval-M结果作为规范参考,并提供了所有评估集上的其他结果。可以看到,在组合注释上训练的模型Train-M+A始终给出最低的错误,这验证了使用自动方法缩放注释的努力。
研究同时表明,混合使用手动和自动注释是提高模型性能的实用解决方案。

图5显示了由UmeTrack、团队的自动标注管道、以及团队训练的以自中心的基线SVEgoNet生成的3D手部姿态的定性示例。
他们从不同的角度对每个模型的预测进行可视化。自中心的基线UmeTrack可以相当好地估计手部姿态。然而,在第三视角视图中的可视化显示,它倾向于沿着z轴产生错误。特别是,在自遮挡(左)或手遮挡(中、右)中,预测的准确性会下降。
另一方面,团队的多视图自动标注利用多个第三视角图像的提示克服了所述缺陷。因此,在注释上训练的SVEgoNet对遮挡情况的结果更加鲁棒。
最后,团队重新审视激励问题:3D手部姿态的质量如何影响动作识别性能?
他们用一种新的评价方案来回答这个问题:以手部姿态为输入的动词分类。在Assembly101中,动作在细粒度级别上定义为描述运动的单个动词和交互对象的组合,例如拿起螺丝刀。团队使用六个动词标签来评估预测的手部姿态,包括pickup拾起,position位置,screw扭紧,putdown放下,remove移除和unscrew扭开。这是因为所述动词严重依赖于用户的手部运动,而手部姿态估计的目的是对其进行编码。
对于动词分类,研究人员使用自为中心的手姿估计器的输出来训练MS-G3D。按照Assembly101的实验,对于每个片段,输入42个关键点的序列(每只手21个)。
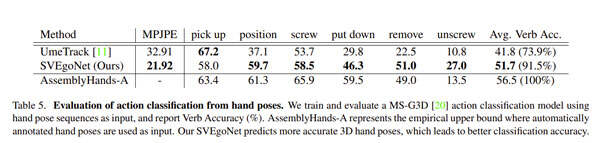
表5报告了从自中心摄像头估计的3D手部姿态的动词分类精度。他们在自动标注上训练了一个动词分类器,平均达到56.5%的动词准确率。他们注意到较低的10hz采样率会影响对快速非线性运动的识别。特别是,拧开螺丝的精度相当低,这主要是由于与螺丝运动混淆。
然后,将我们的单视图SVEgoNet与现成的自中心手部姿态估计器UmeTrack进行比较。其中,UmeTrack用于为Assembly101提供原始注释,并使用来自多个自中心的图像的特征融合模块。
姿态估计度量显示,SVEgoNet达到22.96mmMPJPE,比UmeTrack低38%。其次,对于动词分类精度,使用SVEgoNet预测的手部姿态也大大优于使用UmeTrack(51.7vs.41.8)。

当以56.5的上界性能为参考时,使用SVEgoNet姿态的相对性能达到91.5%,明显优于使用UmeTrack的73.9%。另外,图6给出了UmeTrack和SVEgoNet的分类混淆矩阵。使用SVEg-oNet预测可以显著减少非对角线混淆,特别是对于具有挑战性的动词对。
SVEgoNet分别测量每个动词的性能,在位置、扭紧、放下、移除和扭开螺丝方面,SVEgoNet分别将UmeTrack的动词准确度提高了22%、5%、16%、28%和17%,而拾取的准确度则降低了5%。
对于令人困惑的动词对(拾起和放下),UmeTrack倾向于将两个动词都预测为拾起,因为它们是最常见的动词类。因此,放下的准确率特别低(29.8%),而拾起的准确率为67.2%,略高于SVEgoNet的58.0%。
值得注意的是,团队的模型在位置和移除动词方面的改进是显著的,因为对于所述动词,大多数时候一只手被严重遮挡,而UmeTrack无法预测被遮挡的手的准确姿态。
AssemblyHands:TowardsEgocentricActivityUnderstandingvia3DHandPoseEstimation
总的来说,团队提出了AssemblyHands。这个全新的基准数据集用于研究在强手-物交互存在下的自中心活动。他们使用基于多视图特征聚合的自动标注方法提供了大规模精确的3D手部姿态标注,远远优于原始Assembly101中基于自中心的标注。准确的注释使得他们能够深入分析手部姿态估计如何通知动作识别。
他们同时提出了一种基于动词分类的单视角自中心手部姿态评价方法。研究结果证实,3D手部姿态的质量显著影响动作识别性能。
团队表示,希望AssemblyHands能启发新的方法和见解,从自中心角度来理解人类活动。
在未来的研究中,他们首先计划以更高的采样率将手部姿态注释扩展到整个Assembly101。研究人员同时计划获得对象级别的注释,例如对象boundingbox。最后,他们有兴趣探索手,物体和多任务学习之间的相互作用。







