查看
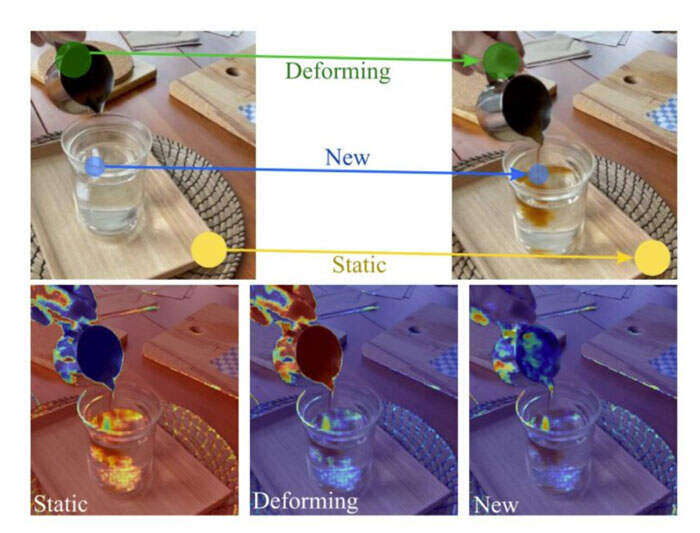
展示了NeRF如何表示动态场景,并从2D图像中学习4D表示
(
将额外的时间维度t引入NeRF的5D表示并不简单。首先,时空点(x,y,z,t)的监控信号比静态点(x、y,z)稀疏。静态场景的多视图图像容易访问,因为你可以移动摄像头,但动态场景中的额外视图需要额外的记录摄像头,从而导致稀疏的输入视图;然后,场景的外观和几何频率沿空间轴和时间轴不同。当从一个位置移动到另一个位置时,内容通常会发生相当大的变化,但背景场景不太可能从一个时间戳完全改变到另一时间戳。时间t维度的频率建模不当导致时间插值性能不佳。
在一篇新的研究论文中,来自布法罗大学、苏黎世联邦理工大学、图宾根大学和InnoPeakTechnology的团队展示了NeRF如何表示动态场景,并从2D图像中学习4D表示。