





编译/VR陀螺
开发下一代高级人工智能需要功能更强大,每秒运算可达50亿次的计算机。
1月24日,Meta宣布已设计并构建了新的AI超计算机AIResearchSuperCluster(RSC),Meta称他们相信这是当今运行速度最快的AI超级计算机之一,待2022年年中完全建成后,RSC则会成为世界上最快的AI超级计算机。
Meta的研究人员已经开始使用RSC来训练用于研究自然语言处理(NLP)和计算机视觉的大型模型,其目标是计划在一天内训练具有数万亿参数的模型。
RSC将帮助Meta的AI研究人员构建可以从数万亿个示例中学习新的更好的AI模型,跨数百种不同语言工作,无缝分析文本、图像和视频,开发新的AR工具等等。
研究人员将能够训练开发先进人工智能比如计算机视觉、自然语言处理、语音识别等所需的最大模型等,借助RSC构建全新的AI系统,该系统将能够做到比如为一群人提供实时语音翻译,每个人都说不同的语言,这样他们就可以在研究项目上无缝协作或一起玩AR游戏。
最终,使用RSC完成的工作将为构建下一代主要计算平台——元宇宙所需的技术铺平道路。人工智能驱动的应用程序和产品将会在元宇宙中扮演重要角色。

 (图源:ai.facebook)
(图源:ai.facebook)
为了充分实现自我监督学习与基于转换器的模型的功用,无论是视觉、语音、语言,还是其他重要用途比如识别有害内容等等,都会需要更大型,更复杂,以及适应性更强的模型。
例如计算机视觉需要以更高的数据采样率处理更大、更长的视频,语音识别需要即使在背景噪音大的挑战性场景(比如派对或音乐会)也能很好的工作,NLP也需要理解更多的语言、方言和口音。除此之外,RSC在其他领域比如机器人技术、具身AI、多模式AI等,都能帮助人们在现实世界中完全有价值的任务。
高性能计算基础设施是训练此类大型模型的关键组成部分,Meta的AI研究团队多年来一直在构建这些高性能系统。我们于2017年设计出第一代的基础设施,单个集群中拥有22,000个NVIDIAV100TensorCoreGPU,每天执行35,000个训练作业。现在,该基础设施在性能、可靠性和生产力方面为Meta的研究人员设定了标准。
2020年初,我们决定采用最佳方式,也就是从头开始设计新的计算基础架构,以利用新的GPU和网络结构技术。我们希望这个基础设施能够在1艾字节(exabyte)大的数据集上训练具有超过一万亿个参数的模型——从规模上看,这相当于36,000年的高质量视频。
尽管高性能计算社区几十年来一直在处理规模问题,但我们还必须确保拥有所有必要的安全和隐私控制措施,以保护我们使用的任何训练数据。与我们之前仅利用开源和其他公开可用数据集的AI研究基础设施不同,RSC还通过允许我们在模型训练中包含来自Meta生产系统的真实示例,帮助我们确保我们的研究有效地转化为实践。
能够帮助推进以及执行下游任务,例如识别我们平台上的有害内容以及具身AI、多模式人工智能,以及帮助改善应用的用户体验。我们相信这是一次在如此大的规模下解决性能、可靠性、安全性和隐私问题。
2、RSC的引擎
AI超级计算机是通过将多个GPU组合成计算节点构建,再通过高性能网络结构连接这些计算节点,以实现这些GPU之间的快速通信。
 (图源:ai.facebook)
(图源:ai.facebook)
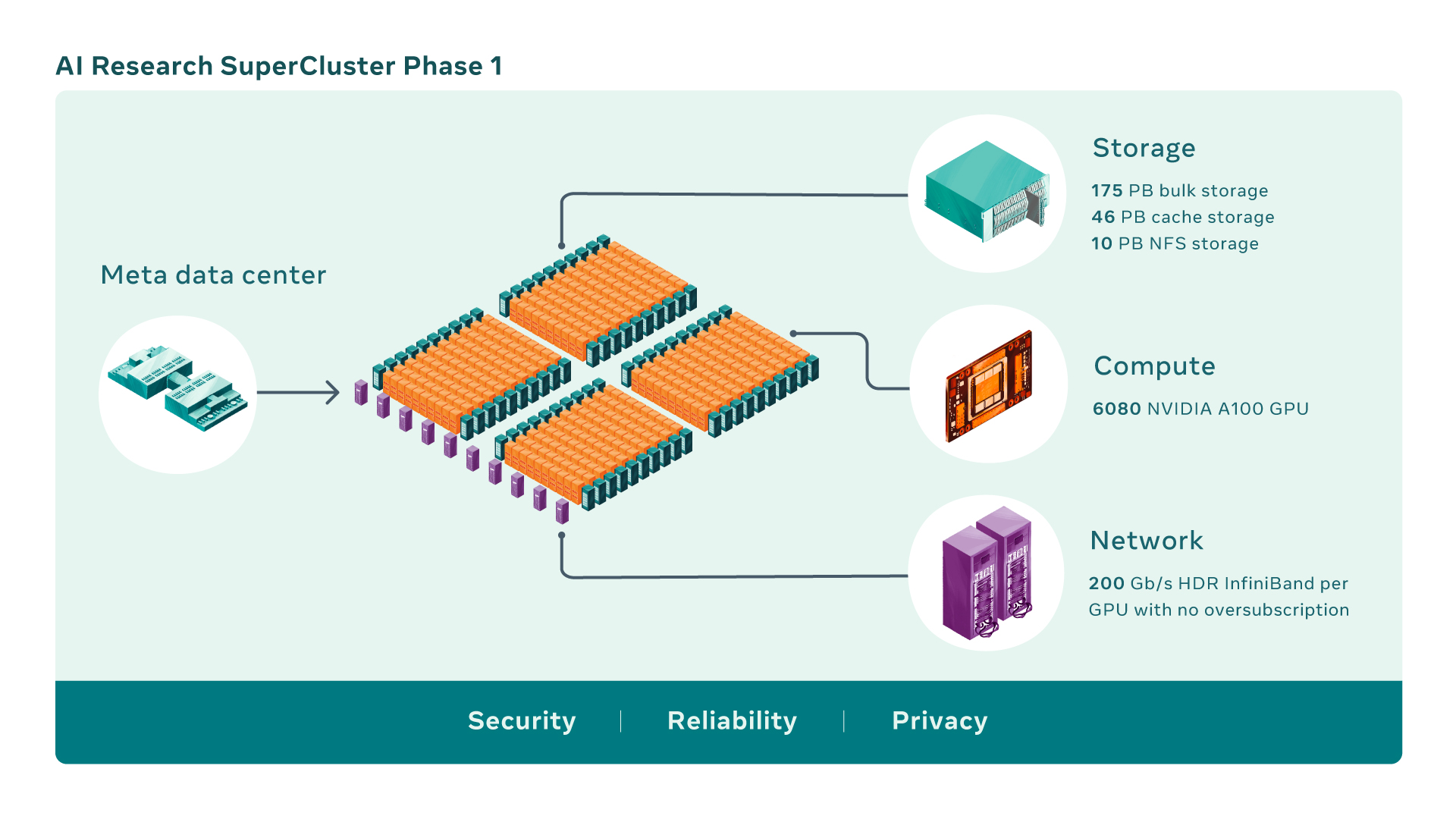
现在,RSC共有760个NVIDIADGXA100系统作为其计算节点,总共有6,080个GPU—每个A100GPU都比我们之前系统中使用的V100更强大。每个DGX通过没有超额订阅的NVIDIAQuantum1600Gb/sInfiniBand两级Clos结构进行通信。RSC的存储层具有175PB的PureStorageFlashArray、46PB的PenguinComputingAltus系统中的缓存存储和10PB的PureStorageFlashBlade。
与Meta的传统生产和研究基础设施相比,RSC的早期基准测试表明,它运行计算机视觉工作流程的速度高达20倍,运行NVIDIA集体通信库(NCCL)的速度超过9倍,训练大规模NLP模型则快三倍。这意味着一个拥有数百亿参数的模型可以在三周内完成训练,而之前是九周。
 (图源:ai.facebook)
(图源:ai.facebook)
3、构建一个AI超计算机......
设计和构建RSC不仅仅是性能问题,而是需要使用当今最先进的技术实现尽可能大的性能。RSC完成后,InfiniBand网络结构将连接16,000个GPU作为端点,使其成为迄今为止部署的最大此类网络之一。此外,我们设计了一个缓存和存储系统,可以提供16TB/s的训练数据,我们计划将其扩展到1EB。
所有这些基础设施都必须非常可靠,我们估计一些实验可能会运行数周并需要数千个GPU。最后,使用RSC的整个体验必须对研究人员友好,以便我们的团队可以轻松探索各种AI模型。
之所以能实现这一目标,很大程度上要归功于与许多长期合作伙伴的合作,他们都在2017年帮助设计了我们的第一代AI基础设施。SGH公司PenguinComputing是我们的架构和托管服务合作伙伴,与我们的硬件集成运营团队部署集群并帮助设置控制平面的主要部分。PureStorage为我们提供了强大且可扩展的存储解决方案。NVIDIA为我们提供了其AI计算技术,包括尖端系统、GPU和InfiniBand结构,以及用于集群的NCCL等软件堆栈组件。
4、大流行所带来的工作挑战
RSC在开发过程中也出现了意想不到的挑战——新冠状病毒大流行。RSC最初是一个完全远程的项目,团队在大约一年半的时间里从一个简单的共享文档变成了一个正常运行的集群。COVID-19和全行业的晶圆供应限制也带来了供应链问题,这使得从芯片到光学元件和GPU等组件,甚至是建筑材料的所有东西都难以获得——所有这些都必须按照新的安全协议进行运输。
 (图源:ai.facebook)
(图源:ai.facebook)
为了有效地构建这个集群,我们必须从头开始设计,创建许多全新的特定于Meta的公约,并在此过程中重新考虑以前的公约。我们必须围绕我们的数据中心设计制定新规则——包括冷却、电源、机架布局、布线和网络(包括全新的控制平面),以及其他重要考虑因素。我们必须确保所有团队,从建筑到硬件,再到软件和人工智能,都在与我们的合作伙伴协调一致地工作。
除了核心系统本身之外,还需要一种强大的存储解决方案,一种可以从EB级存储系统提供TB带宽的解决方案。为了满足AI培训不断增长的带宽和容量需求,我们从头开始开发了一项存储服务AIResearchStore(AIRStore)。
为了针对AI模型进行优化,AIRStore使用了一个新的数据准备阶段,该阶段对要用于训练的数据集进行预处理。一旦进行一次准备,准备好的数据集就可以用于多次训练运行,直到过期。AIRStore还优化了数据传输,从而最大限度地减少Meta数据中心间主干上的跨区域流量。
5、如何保护RSC中的数据
为了构建让使用我们服务的人们受益于新AI模型——无论是检测有害内容还是创造新的AR体验——我们需要使用来自我们生产系统的真实数据来教授模型。
RSC的设计从一开始就考虑到了隐私和安全性,因此Meta的研究人员可以使用加密的用户生成数据安全地训练模型,这些数据直到训练前才被解密。例如,RSC与更大的互联网隔离,没有直接的入站或出站连接,流量只能从Meta的生产数据中心流出。
为了满足我们的隐私和安全要求,从我们的存储系统到GPU的整个数据路径都经过端到端加密,并拥有必要的工具和流程来验证是否始终满足这些要求。
在将数据导入RSC之前,它必须经过隐私审查流程以确认已正确匿名化。然后数据在可用于训练AI模型之前被加密,并定期删除解密密钥以确保旧数据仍然无法访问。由于数据仅在内存中的一个端点进行解密,因此即使在不太可能发生设施物理破坏的情况下,也可以对其进行保护。
6、二阶段之后
RSC于1月24日已经启动并运行,但它的开发仍在进行中。一旦我们完成构建RSC的第二阶段,我们相信它将成为世界上最快的AI超级计算机,其混合精度计算性能接近5exaflops。到2022年,我们会努力将GPU的数量从6,080个增加到16,000个,这将使AI训练性能提高2.5倍以上。InfiniBand结构将扩展为支持16,000个端口,采用两层拓扑结构,不会出现超额订阅。该存储系统将具有16TB/s的目标交付带宽和EB级容量,以满足不断增长的需求。
我们期望计算能力的这种阶跃函数变化不仅使我们能够为我们现有的服务创建更准确的AI模型,而且还能够实现全新的用户体验,尤其是在元宇宙中。我们在自我监督学习和使用RSC构建下一代AI基础设施方面的长期投资正在帮助我们创建基础技术,这些技术将为元界提供动力并推动更广泛的AI社区发展。
来源:







