





背景与挑战:我们距离高逼真的数字世界还有多远?
随着MetaQuest和AppleVisionPro等VR头显的兴起,人们对沉浸式体验的需求愈发强烈。然而,传统2D视频或静态3D模型始终难以突破“真实感”的桎梏,最新的技术也面临着“形似神离”的困境:
●2019年Google提出沉浸式光场(ImmersiveLightField),虽支持6-DoF交互,但受限于固定机位的拍摄方式,仅覆盖场景的正面视角,交互范围有限,且缺乏多模态数据;

●2022年Apple提出沉浸式视频(ImmersiveVideo),虽以高分辨率和环绕式立体声著称,但仅提供3-DoF的观看体验,缺少空间位置的交互自由度。此外,这种呈现方式无法提供真实场景的深度感知,导致视觉系统与前庭感知的冲突,用户在长时间观看后易产生眩晕和疲劳;

●2024年InfiniteReality推出的空间捕获技术(SpatialCapture),通过穹顶式“由外向内(Outside-looking-in)”的采集方案实现了高分辨率、高真实感的动态场景建模。然而,受限于封闭式硬件架构,仅能针对狭小空间内以人或物体为中心的局部场景进行捕捉,缺乏复杂背景细节与自然光照,且设备部署复杂、成本高昂,难以拓展至开放环境或大规模商业应用。

相关成果发表于国际计算机视觉顶级会议IEEECVPR2025并入选为Highlight(亮点工作)。

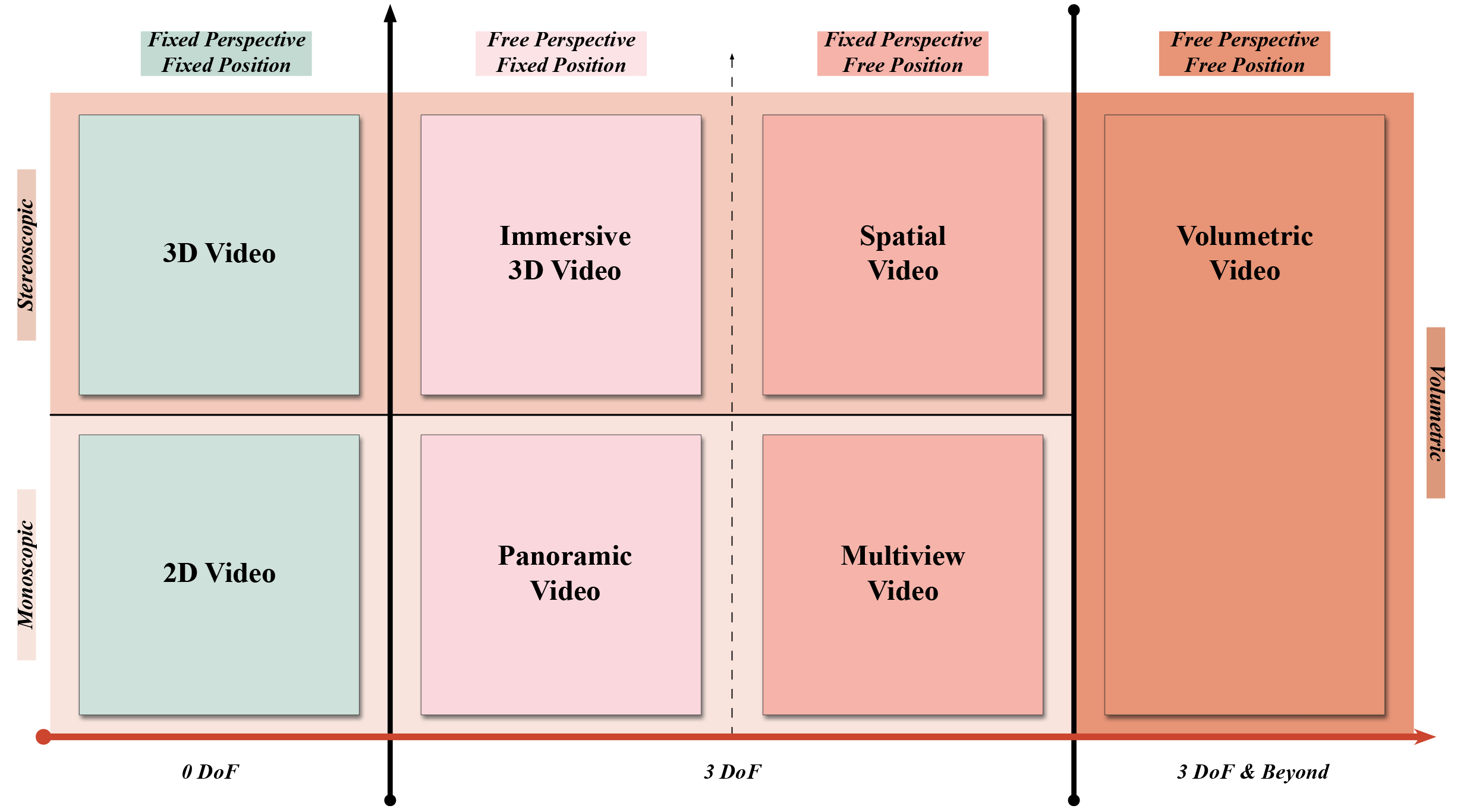
核心贡献:ImViD——沉浸式体积视频全流程制作管线
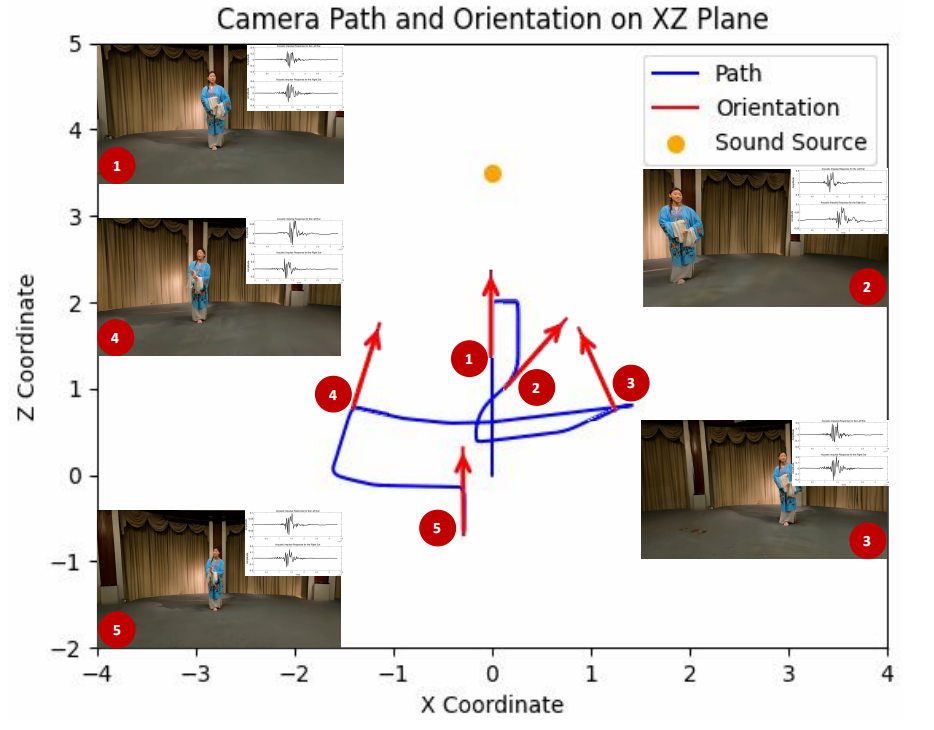
ImViD系统搭建与数据采集
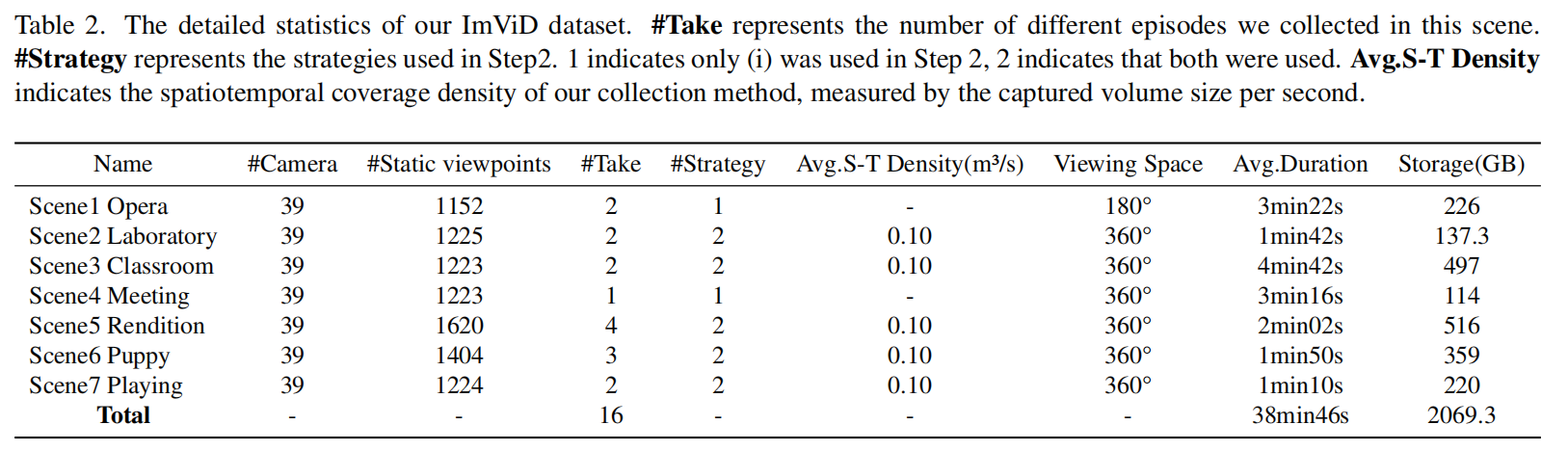
团队设计并搭建了一个可远程控制的移动式平台,搭载46台GoPro摄像机同步触发,可实现高效光、声场采集:
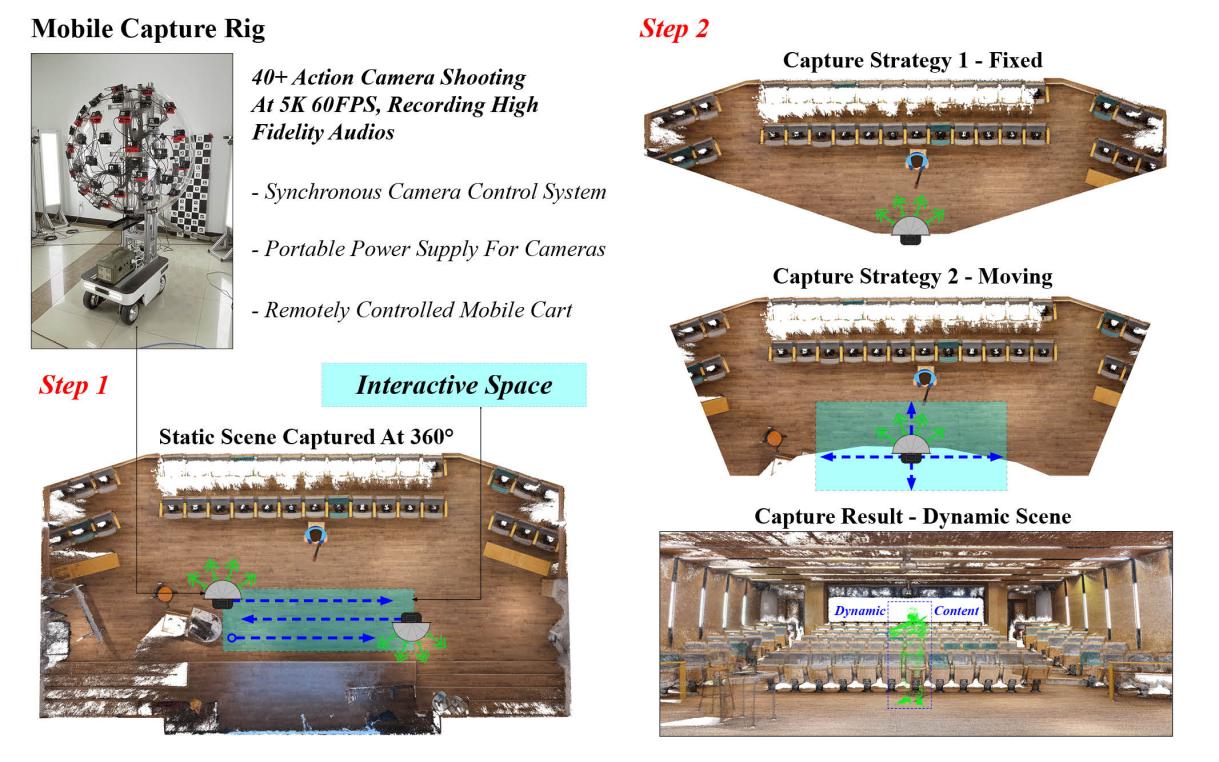
多视角同步音视频采集(分辨率5312×2988,60FPS,1-5min);
定点采集+移动轨迹拍摄模式(支持背景重建与动态前景追踪);
毫米级相机阵列时间同步机制。
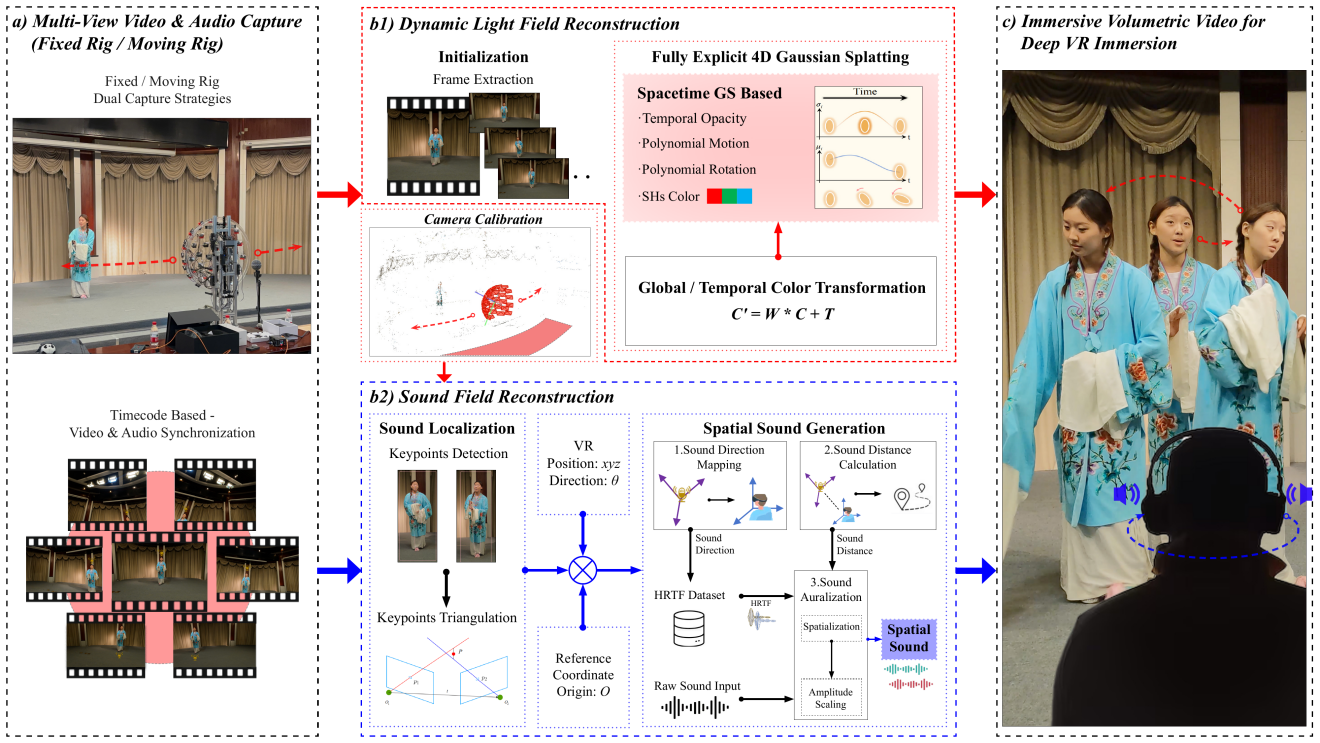
ImViD光声场融合重建
动态光场重建:
作者在SpacetimeGaussian(STG)的基础上,提出了时空一致性更强的改进方法STG++,解决了原方法在动态场景下的漂移与色差问题。
为了消除多相机之间的色彩差异,STG++为每个相机引入仿射颜色变换:
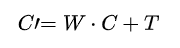
该变换在渲染损失中被联合优化,以确保多视角颜色对齐。此外,作者还在重建过程中对时间维度执行了致密化操作,让高斯在时间维度上也可控。
自由声场重建:
作者提出一种不依赖神经网络训练的几何驱动声场建模方法,基于HRTF(头相关传递函数)和RIR(房间脉冲响应)进行空间音频渲染。具体步骤如下:
(1)声源定位:通过麦克风阵列获取声源位置与用户耳朵位置;
(2)距离衰减建模:计算声源到用户耳朵的距离衰减;
(3)空间音频渲染:基于HRTF和RIR进行空间音频渲染。
从多个同步相机采集的音视频数据构建声场的方案在国内外鲜有团队尝试,但这类采集方式非常贴近人们日常拍摄生活场景的习惯,因此该团队提出的方案具有极大的推广价值。
实验结果:STG++领跑,声场融合,沉浸感拉满!
●光场重建:改进算法STG++以31.24PSNR、110FPS刷新性能,解决色彩闪烁与运动断层难题;

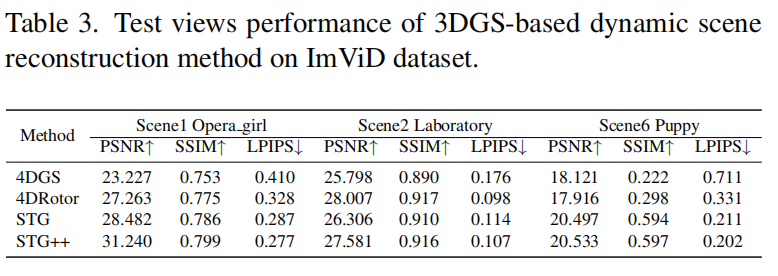
论文结果展示(一)
●声场合成:用户研究显示,61.9%专家认为空间音频感知“优秀”,90%认可沉浸感;
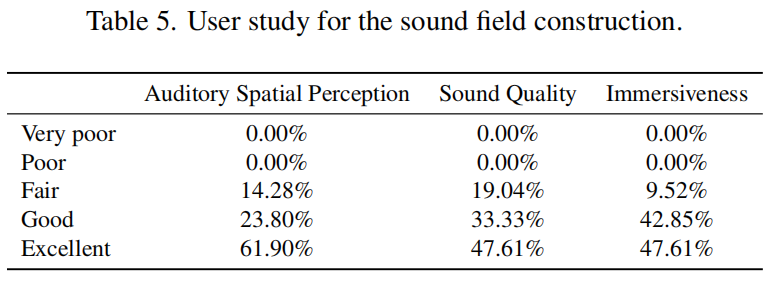
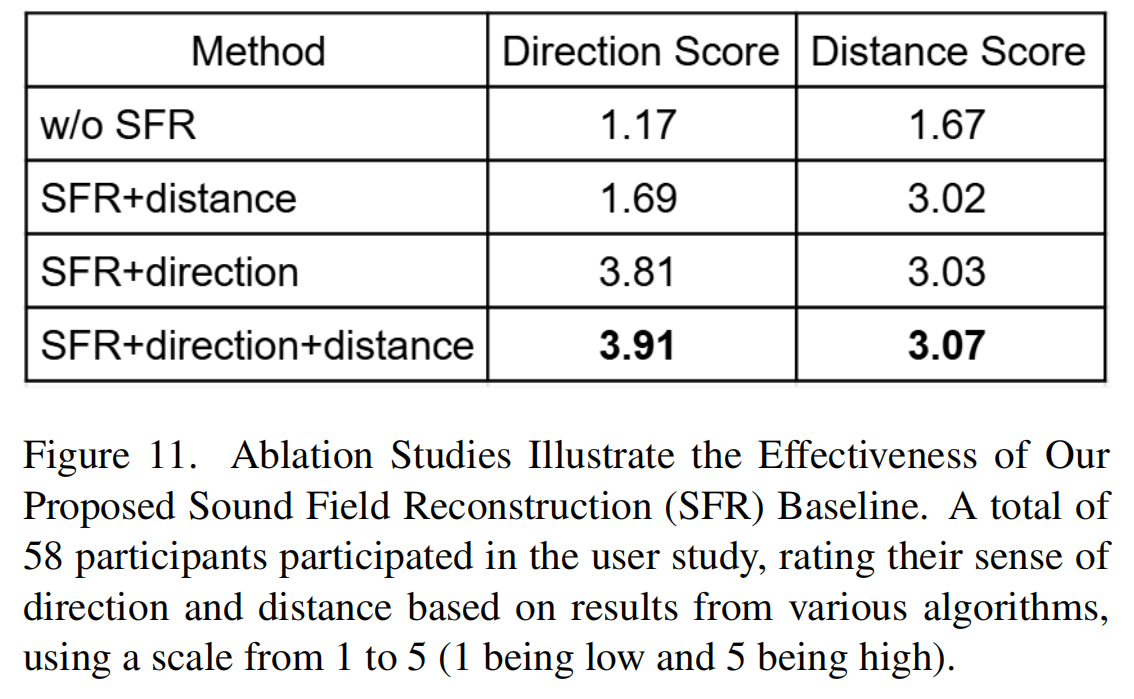
论文结果展示(二)
●实时交互:单卡3090实现6-DoF多模态VR体验,60FPS丝滑渲染,视听反馈随动无延迟!
*声明:企业通稿非VR陀螺官方稿,法律问题一律与VR陀螺无关。







