





查看
在复杂背景和自遮挡场景下生成精确、鲁棒的3D手部网格模型
(
在一项研究中,华南理工大学提出一种并行处理根相关网格和根恢复任务的网络模型。所述模型能够从单目RGB图像中恢复camera空间中的3D手部网格。为了促进端到端训练,团队对2D热图使用了一种隐式学习方法,增强了2D线索在不同子任务之间的兼容性。
实验显示,所述方法提高了模型在复杂环境和自遮挡场景下的预测性能。通过对大规模手部数据集FreiHAND的评估,团队证明了所提出模型与最先进的模型相当。
单目3D网格恢复旨在从单幅图像中提取网格顶点的三维位置。精确的3D网格可以增强AR/VR技术的真实性,从而改善沉浸式体验,提高人机交互的交互性水平。
现有的3D手部网格恢复方法大多关注与预定义的根位置(如手腕)相关的坐标,无法准确确定网格的绝对camera空间坐标。这种限制阻碍了它的适用性,使得不适合精确的交互任务,例如远程医疗手术。
基于摄像头的3D手部网格恢复包括3D重建和空间定位,但由于手部结构的变化和RGB图像中存在深度模糊而面临着挑战。大多数现有的恢复方法通常采用两阶段估计方案。第一阶段通过整合关键手势及其连接来捕获局部结构,第二阶段理解空间语义信息。
但在大多数现有方法中,这两个阶段所使用的网络都是独立且顺序运行,这可能会导致不必要的网络开销,并且在训练过程中效率低下。
另外,由于目前大多数方法要么狭隘地关注局部特征,要么过于关注全局背景,所以难以充分利用图像中固有的尺度信息。因此,在复杂环境下的抗干扰能力和坐标定位的精度将大大降低。
为了在复杂背景和自遮挡场景下生成精确、鲁棒的三维手部网格模型,研究人员提出了一种camera空间3D手部网格恢复模型。
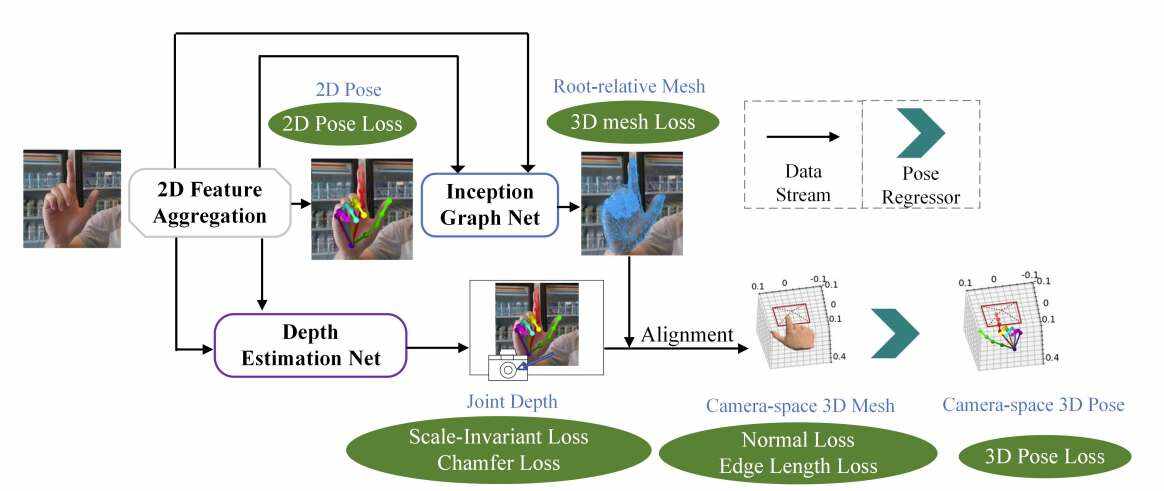
采用两阶段方法,他们将手工网格恢复分为相对根恢复任务和根恢复任务。根相对恢复任务捕获手网格顶点相对于手的根节点的相对位置,而根恢复任务集中于使用boundingbin方法确定手的空间位置。
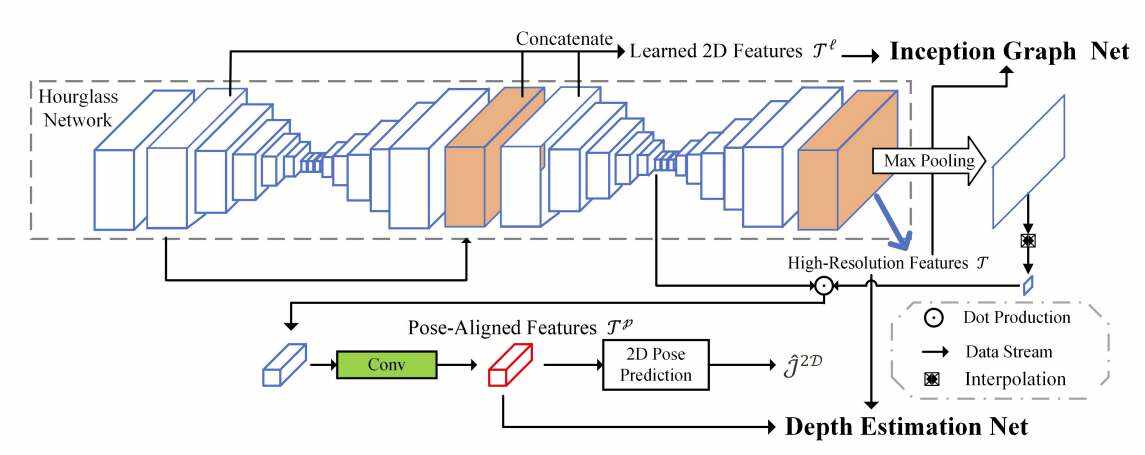
与大多数现有方法不同的是,所提出模型将第一阶段和第二阶段使用的网络整合为一个,既可以进行端到端训练,又降低了复杂度。相关方法采用编码器-解码器架构来获得高分辨率的2D尺度聚合特征作为3D推理的基础线索。
架构已经在多个领域证明了其有效性,包括姿态重建和深度估计。另外,研究人员利用已建立的参数化手部模型MANO来增强推理。为了进行非线性学习并利用网络拓扑中顶点之间的关系进行局部手部形状推断和重建,团队采用了频谱卷积神经网络。这种方法有效地捕捉和利用了手模型内部复杂的空间关系。
为了避免深度估计问题在训练过程中收敛缓慢和次优局部最小值问题,他们将深度估计问题表述为bin中心分类任务。同时,注意机制纳入为指导手特征向深度层次信息学习。通过利用注意力机制,模型可以选择性地关注相关区域2,并有效地学习必要的信息。
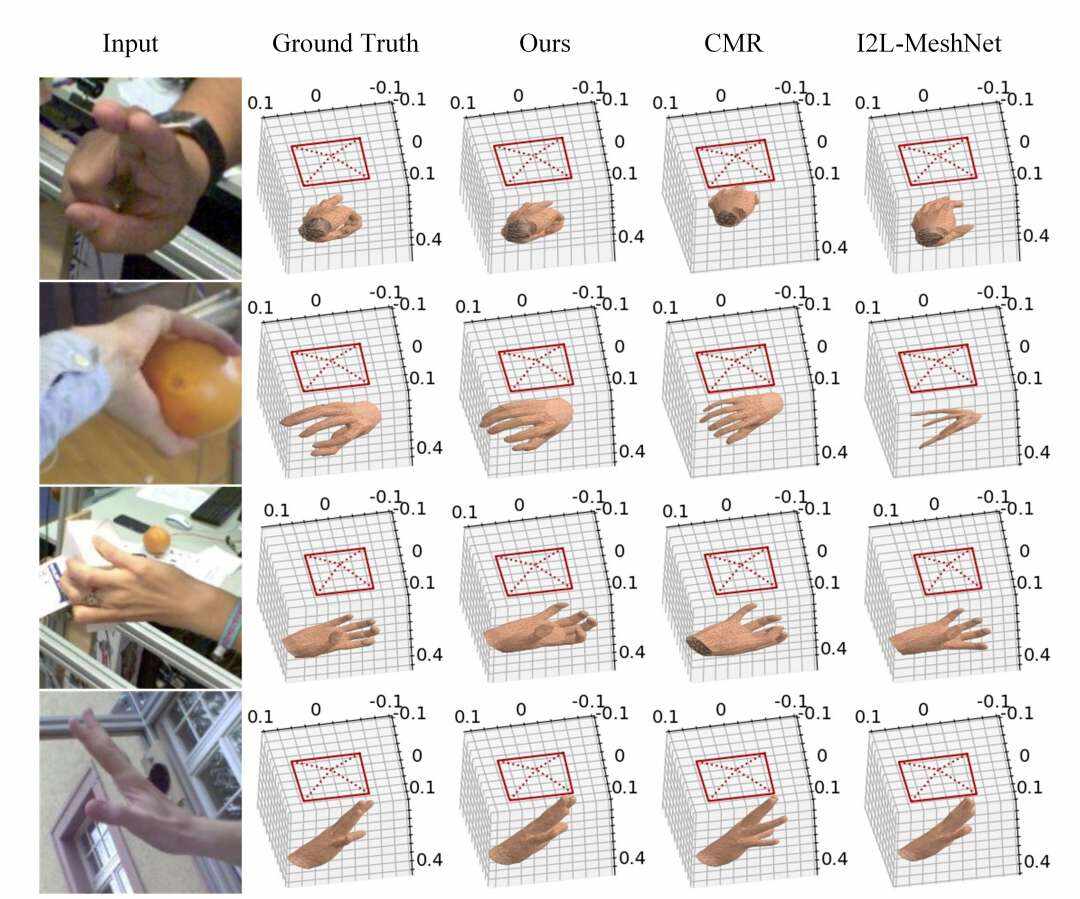
最后,将采集到的信息进行组合,在camera空间中得到所需的3D网格信息。这种来自各种来源的信息的整合使得能够准确地重建手的3D网格表示。利用包含大量复杂背景和自遮挡场景的手部图像的基准数据集FreiHAND,团队对所提出模型的性能进行了评估,并发现所提出模型与最先进的模型相当。
3DHandMeshRecoveryfromMonocularRGBinCameraSpace
总的来说,团队提出了一种并行处理根相对网格和根恢复任务的网络模型,实现了在camera坐标空间中的3D手网格恢复。为了确保收集到的2D热图信息在不同子任务之间的兼容性和有效利用,团队对二维热图采用了内隐学习方法。这种方法在高级语义信息和精细细节之间取得了平衡。
另外,团队设计了一种谱图卷积网络方法,增强了模型在处理复杂环境和自遮挡场景时的预测性能。深度估计表述为一个分类问题,所提出的关注机制结合了局部细节和全局特征。实验结果证实了模型在根相关评估和camera空间评估方面的卓越性能,并且模型优于3D手部网格恢复的SOTA方法。
在这项研究中提出的方法建立了预测绝对空间网格坐标的基本框架,支持端到端两阶段方法的预测,并显著降低了算法部署和管理的复杂性。未来可能的探索方向之一是通过构建轻量级深度神经网络来改进模型。这种优化将促进移动设备的无缝集成,解决计算限制并确保高效的实时处理。







