CMU、MIT大学研究员使用显式体积表示来设计SLAM解决方案
2024-03-13 12:10:34来源:YiVian
查看引用/信息源请点击:映维网Nweon
卡内基梅隆大学和麻省理工学院
(映维网Nweon2024年03月13日)在过去的三十年中,即时定位与映射(SLAM)研究广泛地围绕着映射表示的问题进行,并产生了各种稀疏,密集和神经场景表示。映射表示这项基本选择极大地影响SLAM系统中每个处理模块的设计,以及依赖于SLAM输出的下游任务。
尽管基于映射表示的系统在过去数年中已经成熟到生产水平,但它们依然有重大缺点需要解决。追踪显式表示关键依赖于丰富的3D几何特征和高帧率捕获的可用性。所述方法只能解释观测到的场景部分,但诸如混合现实和高保真3D捕捉等诸多应用都需要能够解释未观察到的/新颖的摄像头视点的技术。
handcrafted表示的缺点,加上用于高质量图像合成的亮度场表示的出现推动了一类尝试将场景编码到神经网络权重空间的方法。这种基于辐射场的SLAM算法受益于高保真的全局映射和图像重建损失,它们可通过可微分渲染捕获密集的光度信息。然而,目前的方法使用隐式神经表征来模拟体积辐射场,这在SLAM设置中导致了众多问题:计算效率低下,不容易编辑,不能明确地模拟空间几何等等。
对于卡内基梅隆大学和麻省理工学院,团队探讨的问题是:如何使用显式的体积表示来设计SLAM解决方案?

具体来说,研究人员使用基于3DGaussians的亮度场来Splat(渲染),Track(追踪)和Map(映射)。他们相信这种表示与现有的映射表示相比有以下优势:
快速渲染和丰富的优化:GaussianSplatting可以以高达400FPS的速度渲染,可以比隐式替代方案更快地进行可视化和优化。快速优化的关键因素是3D原语的栅格化。团队引入了数个简单的修改来提高SLAM的Splatting速度,包括去除view-dependentappearance和使用各向同性Gaussians。另外,这使得团队能够实时使用密集的光度损失进行SLAM,而传统的和隐式的映射表示分别依赖于稀疏的3D几何特征或像素采样来保持效率。
具有明确空间范围的映射:现有映射的空间边界可以很容易地通过在过去观察到的部分场景中添加Gaussians来控制。给定一个新的图像框架,这允许人们通过渲染silhouette来有效地识别场景的哪些部分是新内容。这对于摄像头追踪至关重要,因为研究人员只想将场景的映射区域与新图像进行比较。然而,这对于隐式映射表示非常困难,原因是网络在基于梯度的未映射空间优化期间会受到全局变化的影响。
显式映射:可以通过简单地添加更多的Gaussians来任意增加映射容量。另外,这种明确的体积表示使得能够编辑场景的部分,同时依然允许逼真渲染。隐式方法不能轻易地增加容量或编辑其所表示的场景。
直接梯度流:由于场景是由具有物理3D位置,颜色和大小的Gaussians表示,所以在参数和渲染之间存在直接的,几乎是线性的(投影)梯度流(gradientflow)。因为camera运动可以认为是保持camera静止和移动场景,团队同样可以直接梯度流到camera参数,这使得可以快速优化。基于神经网络的表示没有,因为梯度需要流过(可能很多)非线性神经网络层。
鉴于上述所有优点,明确的体积表示是有效推断高保真空间映射,并同时估计camera运动的自然方法。在模拟和真实数据的实验表明,与之前所有用于camera姿态估计、映射估计和新视图合成的方法相比,团队的方法SplaTAM取得了最先进的结果。
团队表示,SplaTAM是第一个使用3DGaussianSplatting的致密RGB-DSLAM解决方案。通过将世界建模为可以渲染出高保真颜色和深度图像的3DGaussian图像的集合,系统能够直接使用可微分渲染和基于梯度的优化来优化每帧的camera姿态和底层的体积离散化世界映射。
研究人员将场景的底层映射表示为一组3DGaussians。通过仅使用view-independent颜色并强制Gaussians各向同性。这意味着每个Gaussians只有8个参数值。
所述方法的核心是能够以可微分的方式将高保真的颜色、深度和silhouette图像从底层GaussianMap渲染到任何可能的camera参考帧中。这种可微分的渲染允许直接计算底层场景表示和camera参数中相对于渲染和提供的RGB-D帧之间的误差的梯度,并更新Gaussian和camera参数以最小化误差,从而拟合准确的camera姿态和精确的世界体积表示。
GaussianSplatting渲染RGB图像的方法如下:给定一组GaussianSplatting分布和camera姿态,首先对所有Gaussian从前到后进行排序。然后,RGB图像可以通过在像素空间中按顺序对每个Gaussian的splatted2D投影进行alpha合成来有效地渲染。
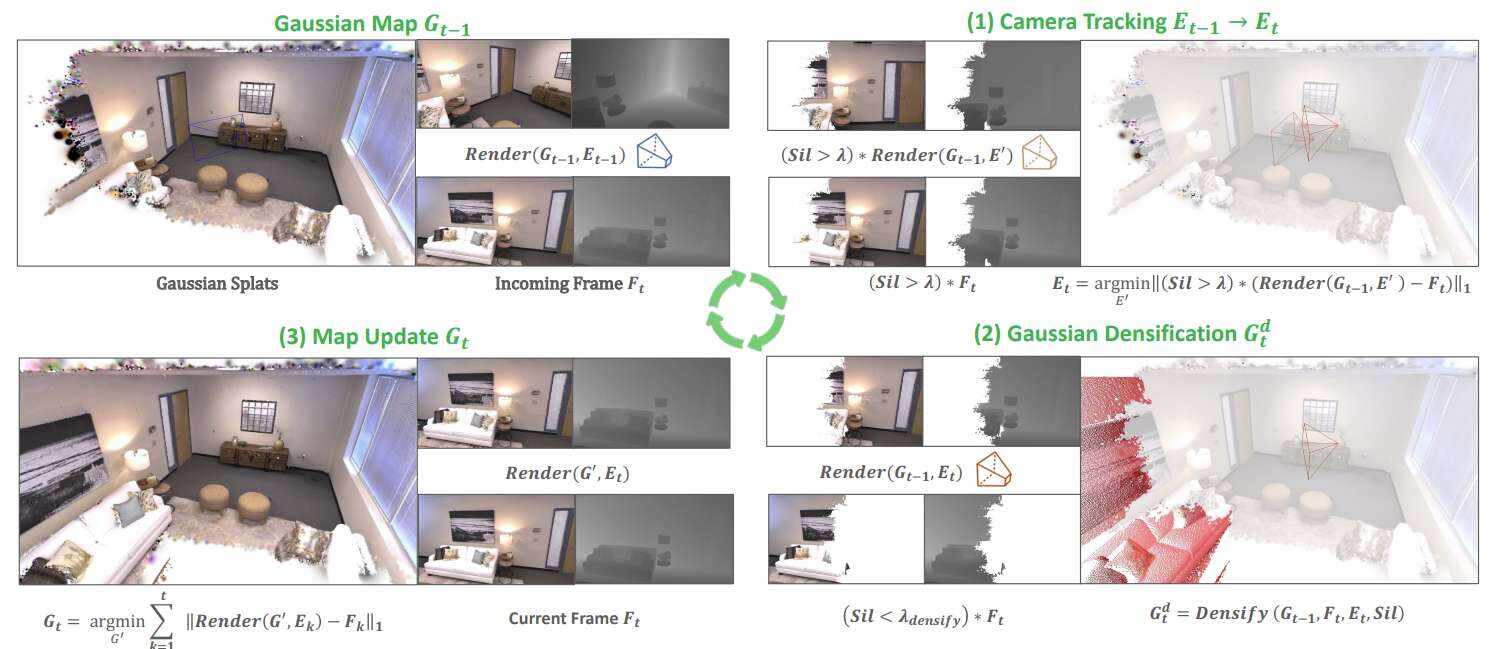
研究人员从Gaussian表示和可微渲染器中构建了一个SLAM系统。假设有一个已经从一组camera帧1到t进行了拟合的现有映射。给定一个新的RGB-D帧t+1,SLAM系统执行如图2所示的步骤:
camera追踪:相对于t+1的camera姿态参数,将RGB-D帧的图像和深度重建误差最小化,但仅评估可见silhouette内像素的误差
Gaussian致密化:根据渲染silhouette和输入深度向映射添加新的Gaussian。
映射更新:给定从第1帧到第t+1帧的camera姿态,通过最小化所有图像的RGB和深度误差来更新场景中所有Gaussian的参数,直到t+1。在实践中,为了保持批处理大小可管理,优化与最近帧重叠的关键帧的选定子集。
研究人员在四个数据集评估了所提出的方法:scannet++、Replica、TUM-RGBD和原始ScanNet。选择后三种方法是为了遵循之前基于辐射场的SLAM方法Point-SLAM和NICE-SLAM的评估程序。然而,他们添加scannet++评估,因为其他三个基准都没有能力评估新视图的渲染质量,只能评估训练视图的camera姿态估计和渲染。
Replica是最简单的基准,因为它包含了合成场景,高度精确和完整的(合成)深度图,并且连续camera姿态之间的位移很小。TUM-RGBD和原始ScanNet更难,特别是对于致密方法,因为它们都使用旧的低质量camera,所以RGB和深度图像质量较差。深度图像非常稀疏,有很多缺失的信息,而彩色图像有非常高的运动模糊。
对于ScanNet++,团队使用了来自两个场景(8b5caf3398(S1)和b20a261fdf(S2))的单反捕获,其中包含完整的密集轨迹。与其他基准相比,scannet++的颜色和深度图像质量非常高,并为每个场景提供第二个捕获循环以评估完全新颖的视图。
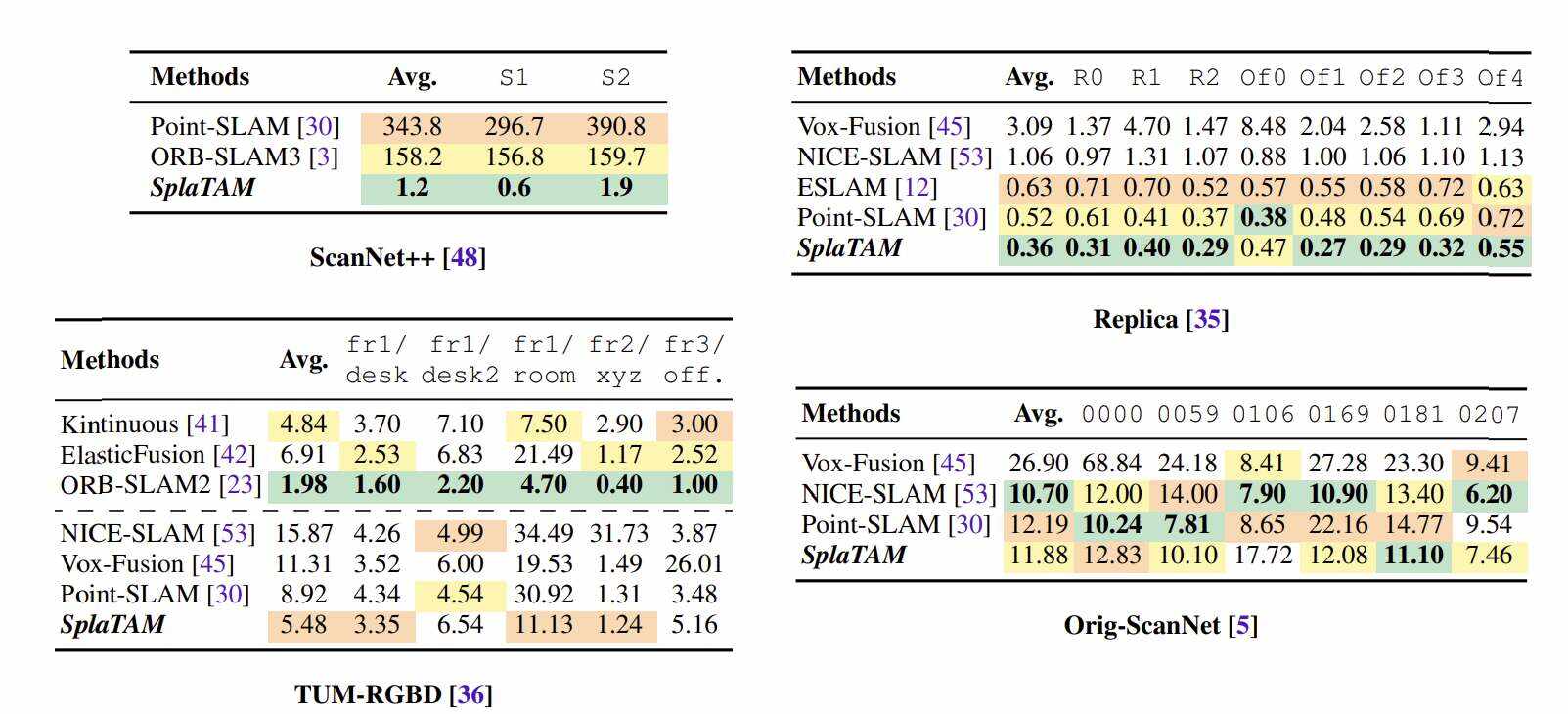
在表1中,团队将所提出方法的camera姿态估计结果与四个数据集的一系列基线进行了比较。在scannet++,SOTASLAM方法Point-SLAM和ORB-SLAM3由于相邻camera之间的位移非常大,完全无法正确追踪camera姿态,从而产生非常大的姿态估计误差。特别是,对于ORB-SLAM3,观察到无纹理的ScanNet++扫描由于缺乏特征而导致追踪重新初始化多次。相比之下,团队的方法成功地在两个序列追踪camera,平均轨迹误差仅为1.2cm。
在Replica数据集,即之前事实上的评估基准,团队所提出的方法将先前SOTA的轨迹误差从0.52cm减少到0.36cm,降幅超过30%。
在TUM-RGBD,由于深度传感器信息差(非常稀疏)和RGB图像质量差(极高的运动模糊),所有的体积测量方法都非常困难。然而,与这一类别中的先前方法相比,团队提出的方法依然明显优于先前的SOTA,将轨迹误差降低了近40%,从8.92cm降至5.48cm。但对于这个基准,基于特征的稀疏追踪方法依然致密方法,如ORB-SLAM2。
原始ScanNet基准测试与TUM-RGBD存在类似的问题,因此没有密集体积方法能够获得小于10cm轨迹误差的结果。在这个基准测试中,团队所提出方法的性能与之前的两种SOTA方法相似。
总的来说,上述camera姿态估计结果非常有希望,并展示了SplaTAM方法的优势。scannet++的结果表明,如果你有高质量的clean输入图像,即便camera位置之间有极大的运动,团队的方法可以成功准确地执行SLAM,这是以前的SOTA方法所不可能做到的事情。

在图3中,团队展示了对来自scannet++的两个序列重建的GaussianMap的可视化结果。可以看到,这些重建在几何形状和视觉外观方面都具有令人难以置信的高质量。这是使用基于3DGaussianSplatting的映射表示的主要优势之一。
团队同时展示了由所提出方法估计的camera轨迹和camera姿态截锥体覆盖在映射上。我们可以很容易地看到在连续相机姿态之间经常发生的大位移,这使得这成为一个非常困难的SLAM基准,然而我们的方法却能非常准确地解决这个问题。

如表2所示,他们在Replica数据集的输入视图评估了所提出方法的渲染质量。研究人员的方法获得了与PointSLAM相似的PSNR、SSIM和LPIPS结果,但这个比较并不公平,因为PointSLAM具有不公平的优势,它将图像的ground-truth深度作为输入,以便对其3D体积进行采样以进行渲染。
团队的方法比其他基线Vox-Fusion和NICESLAM取得了更好的结果,在PSNR方面比两者都提高了约10dB。

另外在scannet++基准测试中,新视图和训练视图呈现的结果可见表3。团队所提出的方法获得了较好的新视图合成结果,平均PSNR为24.41,而训练视图的PSNR略高,为27.98。同时,团队提出的方法获得了令人难以置信的精确重建,在新视图中深度误差仅为2cm左右,在训练视图中深度误差为1.3cm。优异的重建效果可以从图3中看到。
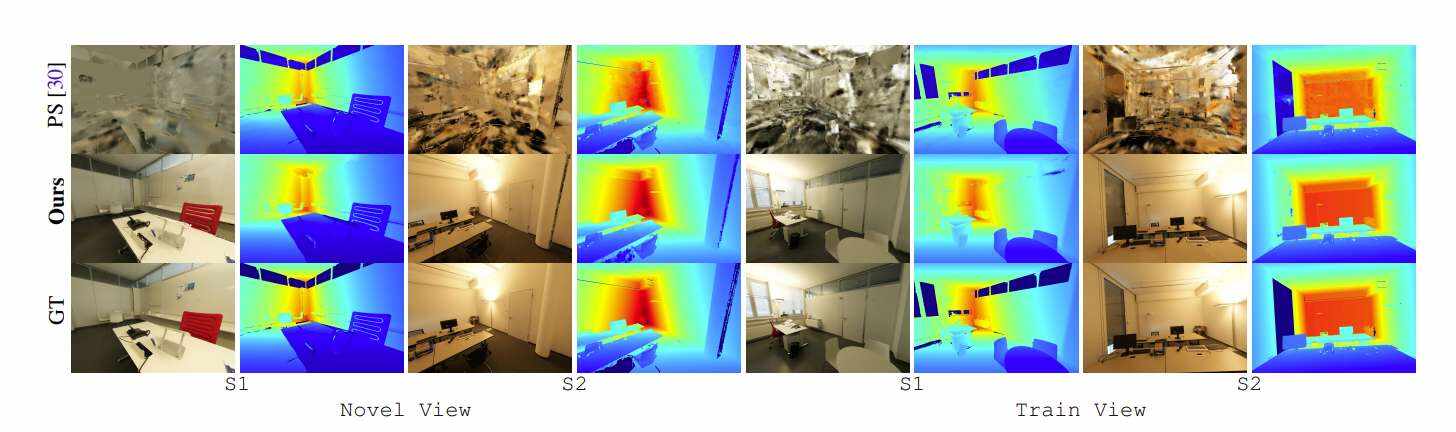
基于RGB和深度的新视图和训练视图渲染的视觉结果如图4所示。可以看到,团队所提出的方法在新视图和训练视图的两个场景方面都取得了很好的效果。相比之下,Point-SLAM在camera姿态追踪和训练视图的过拟合方面失败,并且根本无法成功渲染新视图。Point-SLAM同时将ground-truth深度作为渲染的输入,以确定在哪里采样,所以深度图看起来与ground-truth相似,但颜色渲染则完全错误。
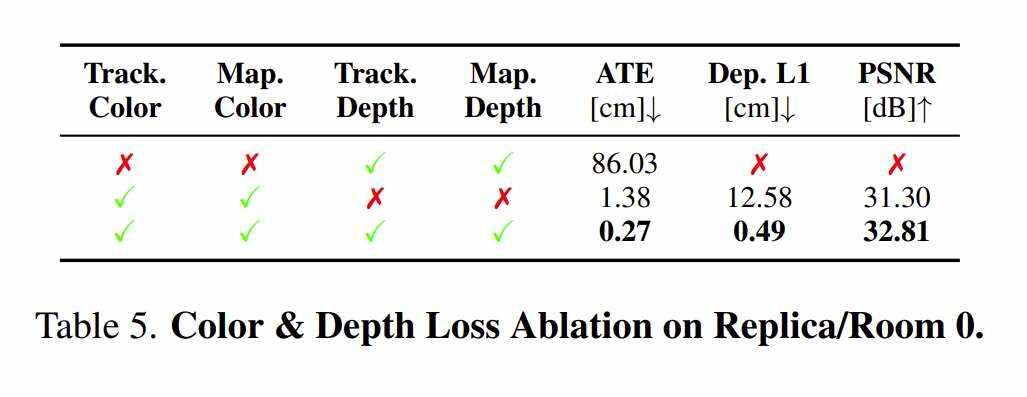
SplaTAM涉及使用光度(RGB)和深度损失拟合camera姿态和场景映射。在表5中,他们放弃了两者都使用的决定,并研究了在追踪和映射中只使用其中一个或另一个的性能。他们使用Replica的Room0来进行探索。
仅使用深度,团队所提出的方法完全无法追踪camera轨迹,因为L1深度损失不能在x-y图像平面提供足够的信息。仅使用RGB损失可以成功追踪camera轨迹(但两者的误差超过5倍)。RGB和深度一起工作可以达到很好的效果。对于仅考虑颜色损失,重建的PSNR非常高,仅比完整模型低1.5PSNR。但与直接优化深度误差相比,仅使用颜色的深度L1要高得多。在纯色实验中,深度不用作追踪或映射的损失,而是用于Gaussian的致密化和初始化。
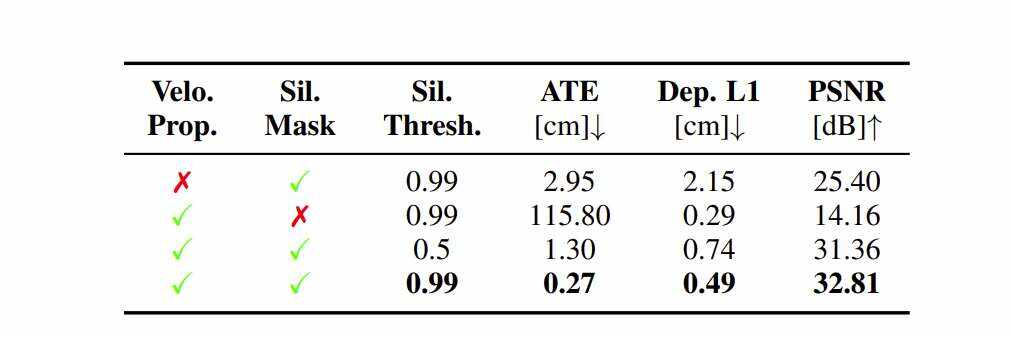
在表4中,剔除了camera追踪的三个方面:使用前向速度传播;使用silhouette掩码来掩盖损失中的无效映射区域;将silhouette阈值设置为0.99而不是0.5。这三点对于取得优异成绩至关重要。没有前向速度传播追踪依然有效,但总体误差超过10倍。silhouette非常重要,因为没有silhouette,追踪就完全失败。将silhouette阈值设置为0.99允许将损失应用于映射中优化的像素,从而导致与用于密度化的阈值0.5相比,误差减少了5倍。
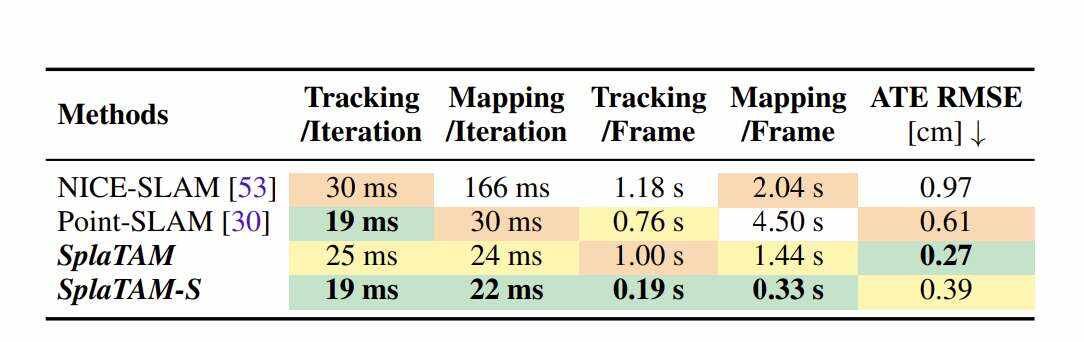
表6比较了运行时间(NvidiaRTX3080Ti)。团队所提出方法的每次迭代渲染一个完整的1200×980像素的图像(~120万像素),而其他方法仅使用200个像素进行追踪,1000个像素用于映射每个迭代(但尝试巧妙地采样像素)。尽管团队所提出方法可以渲染3个数量级的像素,但运行时间类似,这主要是由于栅格化3DGaussian的效率。
另外,团队所提出方法的其中一个版本具有更少的迭代和半分辨率密度SplaTAM-S。它的工作速度快了5倍,而性能只有轻微的下降。特别是,SplaTAM在Replica每帧分别使用40和60次迭代进行追踪和映射,而SplaTAM-s每帧使用10和15次迭代。
当然,研究人员坦诚,尽管SplaTAM达到了最先进的性能,但他们发现这一方法对运动模糊、大深度噪点和剧烈旋转表现出一定的敏感性。团队认为一个可能的解决办法是暂时模拟所述影响,并希望在今后的研究中解决这个问题。另外,方法需要已知的camera特征和密集深度作为执行SLAM的输入,消除所述依赖关系是未来一个有趣的途径。
SplaTAM:Splat,Track&Map3DGaussiansforDenseRGB-DSLAM
总的来说,卡内基梅隆大学和麻省理工学院的研究人员提出了一种全新的SLAM系统SplaTAM,它可以利用3DGaussiansSplatting辐射场作为其底层映射表示,并能够实现更快的渲染和优化,明确的映射空间范围知识,同时简化了映射密度。实验证明了它在实现camera姿态估计,场景重建和新视图合成的最先进结果方面的有效性。
团队相信,SplaTAM不仅在SLAM和新视图合成领域树立了新的基准,而且开辟了令人兴奋的途径,其中3DGaussiansSplatting与SLAM的集成将为场景理解的进一步探索和创新提供一个强大的框架。研究强调了这种集成的潜力,并为未来更复杂、更有效的SLAM系统铺平了道路。













