





查看
高效的多任务解决方案,使得系统的计算成本较低
(
现有的场景分割和/或目标追踪解决方案有一定的局限性。例如,用于对象追踪的解决方案的示例包括在前一帧中目标对象的位置附近的区域中执行本地搜索。然而,执行这种局部搜索依赖于基于前一帧的预测,这可能适合于短期追踪,但不能用于在大量帧(例如超过5帧)重新检测目标对象。
用于对象追踪解决方案的另一个示例包括通过基于对象检测结果搜索目标对象来执行检测和追踪。这种解决方案的一个问题是,它依赖于对象检测。这有一定的问题。例如,对象检测受到可检测的预定义类的限制,不属于预定义类的任何对象都无法检测到。另外,目标检测是一个复杂的过程,需要大量的计算资源。
另一种解决方案涉及使用单独的分割和追踪模型,但由于使用两个模型,这可能具有很高的计算成本。
联合场景分割和一次性长期目标追踪是一种理想的解决方案,它允许系统利用场景分割的特征在多个帧对一个或多个目标对象执行对象追踪。这样的解决方案可以实现实时视频分割和追踪。
在名为“Scenesegmentationandobjecttracking”的
对于一次长期目标追踪和分割,场景分割和目标追踪系统可以进行一次学习,以学习初始帧中定义的新对象。场景分割和对象追踪系统可以执行长期追踪。目标分割可以将追踪的目标对象从背景中分割出来。
高通表示,所述技术提供了一种高效的多任务解决方案,可使用语义场景特征进行语义分割和长期一次性对象追踪和分割,使得系统的计算成本较低。

图1是示出场景分割和对象追踪系统100的架构的框图。场景分割和对象追踪系统100包括用于追踪视频帧序列中的对象的各种组件,所述视频帧序列可包括一个或多个输入帧101。如图所示,场景分割和目标追踪系统100的组件包括语义提取引擎102、特征记忆104、交叉注意引擎106和预测引擎108。
场景分割和对象追踪系统100可以处理至少有一个目标对象位于其中的场景的帧序列。帧序列可以包括一个或多个输入帧101。
在一个实施例中,帧序列可以由场景分割和对象追踪系统100的一个或多个图像捕获设备捕获。在一个说明性示例中,场景分割和对象追踪系统100可以包括一个RGB摄像头或多个RGB摄像头。在另一个示例中,场景分割和目标追踪系统100可以包括一个或多个红外摄像头和一个或多个RGB摄像头。
语义提取引擎102可以处理来自所述一个或多个帧101的帧,从而为所述帧生成一个或多个分割掩码103。一个或多个分割掩码103可包括对所述帧中的每个像素的各自分类。例如,如果帧包含人、树、草和天空,则语义提取引擎102可以将特定像素分类为“人”类、“树”类、“草”类或“天空”类。
在生成一个或多个分割掩码103时,语义提取引擎102可以生成多个特征。例如,语义提取引擎102可以包括或是经过训练以执行语义分割的神经网络的一部分。
所述神经网络可包括至少一个隐藏层,隐藏层生成一个或多个特征向量或其他特征表示,以表示来自所述一个或多个帧101的每一帧的特征。神经网络的每个隐藏层可以从前一个隐藏层提供的输入生成一个或多个特征向量。语义提取引擎102可以从一个或多个隐藏层提取或输出特征到特征存储器104。
在一个实施例中,语义提取引擎102的输出输出到特征存储器104。特征存储器104可存储由语义提取引擎102为所述一个或多个输入帧101的每一帧提取的特征。存储在特征存储器104中的特征可以表示前景和背景。
当语义提取引擎102处理每个新的输入帧时,特征存储器104或系统100的处理设备可以基于从新输入帧提取的特征更新存储在特征存储器104中的特征。
在一个实施例中,当来自预测引擎108的预测置信度小于置信度阈值时,特征存储器104或处理设备可以暂停更新特征存储器104。
在一个实施例中,特征存储器104或处理设备可以选择不确定性小于不确定性阈值的特征来更新特征存储器104。从初始帧提取的特征保留在特征存储器104中。
例如对于一个或多个输入帧101的初始帧,场景分割和对象追踪系统100可以使用前景-背景掩码105来学习特定帧的前景和背景。前景-背景掩码105可以是二进制掩码,包括表示相应输入帧中的目标对象的第一值和表示相应输入帧中的背景的第二值的像素。
语义提取引擎102可以使用前景-背景掩码105来指导对相应输入帧。在一个实施例中,前景-背景掩码105仅用于初始帧,以初始化为帧序列存储在特征存储器104中的特征。场景分割和目标追踪系统100可以处理帧序列中的后续输入帧,而不使用前景-背景掩码作为输入。
在追踪期间,语义提取引擎102可以生成一个或多个分割掩码103并提取可被场景分割和对象追踪系统100用于追踪帧序列中的至少一个目标对象的特征。例如,语义提取引擎102可以将从当前输入帧提取的特征输出到交叉注意引擎106。
如上所述,特征表示前景和背景。交叉注意引擎106可从特征存储器104获得所存储的特征。交叉注意引擎106可以将所存储的特征与从当前输入帧提取的特征进行比较,以生成表示当前帧的前景和背景的组合表示。
交叉注意引擎106可向预测引擎108输出所述组合表示或特征。预测引擎108基于前景和当前输入帧的背景在组合表示或特征中的表示确定或预测目标对象在当前输入帧中的位置,从而生成预测结果107。
在一个实施例中,预测引擎108可以生成表示目标对象位置的边界框。预测引擎108同时可以生成前景-背景掩码。前景-背景掩码可用于基于从当前帧提取的特征更新特征存储器104。
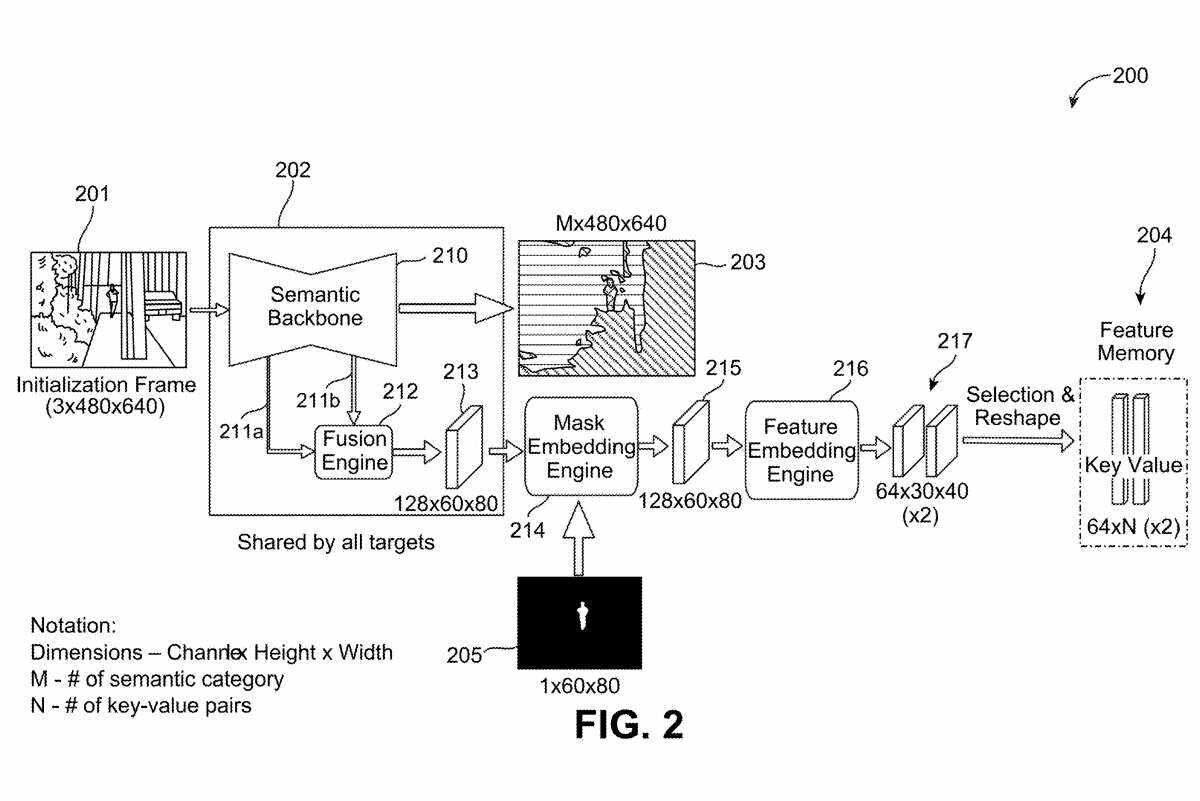
图2是示出场景分割和对象追踪系统200的示例框图。场景分割和对象追踪系统200是场景分割和对象追踪系统100的示例实施例,用于初始化用于对由场景的一个或多个帧捕获的一个或多个目标对象执行对象追踪的系统。
例如,场景分割和对象追踪系统200可以使用初始化帧201来初始化用于追踪的场景分割和对象追踪系统。所述初始化帧201可包括所述场景的帧序列的初始帧。
在一个说明性示例中,初始化帧201可以具有具有3个颜色通道的480像素×640像素的分辨率,如图2所示为3×480×640。初始化帧201可以具有任何其他合适的分辨率或颜色通道的数量。
语义提取引擎202包括用于执行语义分割和特征提取的语义主干210。语义主干210可以包括机器学习系统,例如经过训练以执行语义分割的神经网络。例如,语义主干210可以实现为使用基于监督学习、半监督学习或无监督学习的多个训练帧或图像进行训练的编码器-解码器神经网络。
语义主干210可以处理初始化帧201以生成一个或多个分段掩码203。类似于一个或多个分割掩码103,一个或多个分割掩码203可以包括初始化帧201中每个像素的相应分类。
如图2所示,初始化帧201包括帧201中间的一个人和其他背景信息。所述人的身体分类为第一类,所述人的脸分类为第二类,所述帧201中的树叶分类为第三类,所述帧201中的建筑物被分类为第四类,如所述一个或多个分割掩码203中的不同图案所示。
一个或多个分段掩码203可以是任何合适的大小。在图2所示的示例中,一个或多个分割掩码203的分辨率为480×640,与初始化帧201的分辨率相匹配,深度为M,对应于语义类别的数量,从而得到M×480×640分割掩码。
在一个例子中,在上面的“人”类、“脸”类、“树叶”类和“建筑”类的例子中,M可以等于4。在这样的示例中,存在4个以上的语义类别,但初始化帧201中的对象都不对应于训练语义主干210对其进行分类的附加语义类别。
一个或多个分割掩码203可用于包括场景分割和对象追踪系统200或与场景分割和对象追踪系统200分离的系统中的一个或多个处理。例如,摄像头系统可以使用分割掩码来处理帧,例如以不同的方式处理图像的不同部分。
语义主干210生成多个特征,作为生成一个或多个分割掩码203的过程的一部分。例如在用于语义主干210的神经网络实现的示例中,神经网络的每个隐藏层可以在特定深度输出具有特定分辨率的一个或多个特征图。
在编码器-解码器神经网络的示例中,编码器部分的每个后续隐藏层可以输出与前一个隐藏层相比具有较小分辨率的特征映射,而解码器部分的每个后续隐藏层可以输出与前一个隐藏层相比具有较大分辨率的特征映射。
在一个实施例中,场景分割和对象追踪系统200可用于追踪多个对象。在这种多目标追踪情况下,所有目标对象可以共享相同的提取特征,以便语义主干210只对初始化帧201运行一次。
语义提取引擎202可从语义主干210提取特征,并将提取的特征输出到语义提取引擎202的融合引擎212。例如,构成语义主干210的神经网络的每个隐藏层可以输出具有不同分辨率或比例的特征图。语义主干210可以从一个或多个隐藏层提取特征映射,并将所述特征映射输出到融合引擎212。
语义提取引擎202可将融合特征213输出到掩码嵌入引擎214。所述掩码嵌入引擎214可以使用所述融合特征213和前景-背景掩码205来学习所述初始化帧201的前景和背景。
在一个实施例中,掩码嵌入引擎214可以使用前景-背景掩码105来指导学习与前景相对应的融合特征213的特征和与初始化帧201的背景相对应的融合特征213的特征,从而可以提供对初始化帧201中所描绘的场景的前景和背景的一次性学习。
例如,掩码嵌入引擎214可以将为初始化帧201生成的融合特征213与前景-背景掩码205组合以生成修改的特征215。在一个说明性示例中,为了将融合特征213与前景-背景掩码205结合,掩码嵌入引擎214可以将前景-背景掩码205嵌入到具有卷积层的特定尺寸的特征(用x表示)中,并且可以将特征x添加到融合特征213中。
将特征x与融合特征213相加的和可以输出到另一个卷积层以生成修改后的特征215。修改后的特征215可以具有与图2所示的融合特征213相同的尺寸和深度,或者可以具有不同的分辨率和/或深度。
在一个实施例中,前景-背景掩码仅可用于初始化帧201,以初始化存储在特征存储器204中的用于帧序列的特征。在这方面,场景分割和对象追踪系统200可以处理帧序列中的后续输入帧,而无需使用前景-背景蒙版作为执行追踪的输入。
所述修改的特征215可输出到特征嵌入引擎216,所述特征嵌入引擎216可进一步将所述修改的特征215嵌入为键值对217以初始化所述特征存储器204。如图2所示,键值对217可以包括两个特征映射,每个特征映射的维度为30×40,深度为64通道。键值对217可以被重塑为一个维度64×N(×2),其中64是通道的数量,N对应于存储在特征存储器204中的键值对的数量,×2表示有两个64×N张量或向量。
在这个示例中,有N个键和N个值,每个键和值都是一个64维张量或向量。存储在特征存储器104中的特征的初始存储的键值对可以表示前景和初始化帧201的背景。
当帧序列的每个后续帧由语义提取引擎202处理时,存储在特征存储器104中的特征可以基于新提取的特征进行更新。
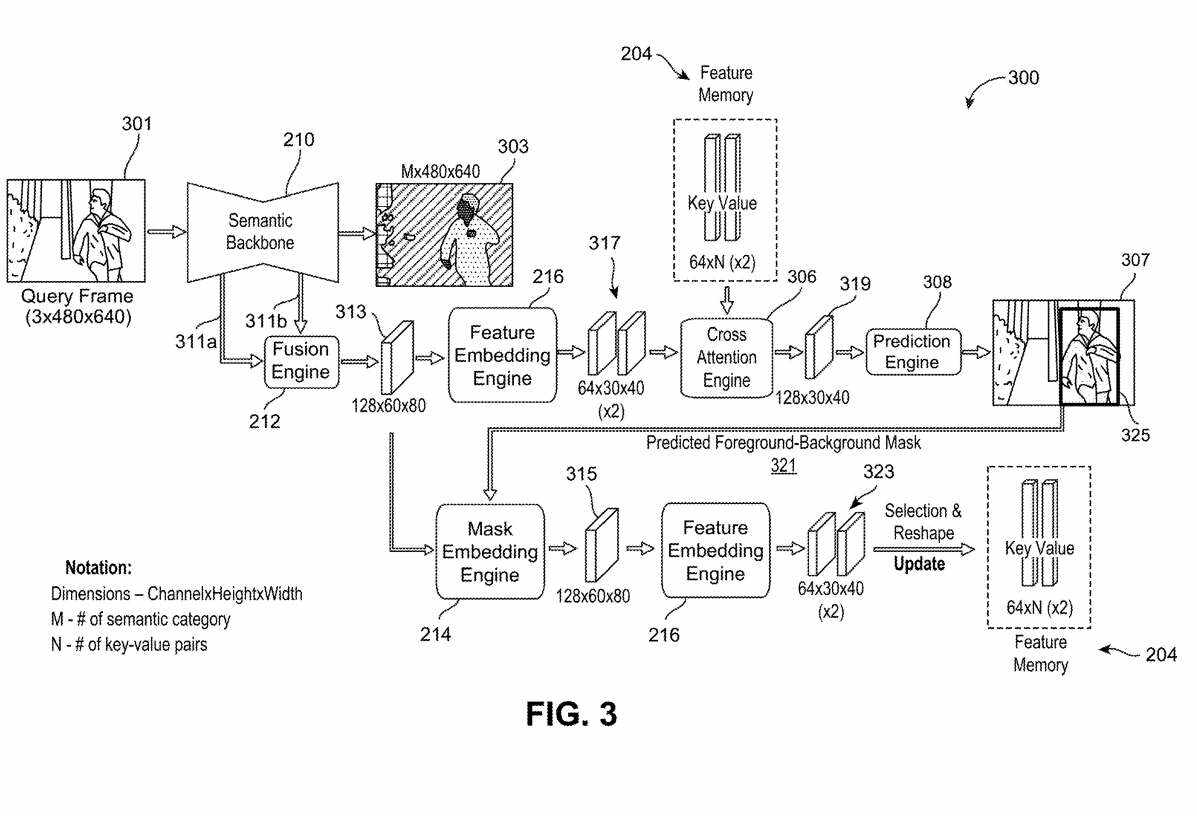
图3是示出场景分割和对象追踪系统300的示例的框图,所述系统用于在上述关于图2的帧序列的初始化帧201之后的一个或多个帧中对一个或多个目标对象执行预测以进行对象追踪。
场景分割和对象追踪系统300可以基于通过交叉注意执行的全局搜索来执行用于对象追踪的预测。
在一个实施例中,场景分割与对象追踪系统300是场景分割与对象追踪系统100在对所述帧序列的一个或多个查询帧中的一个或多个目标对象执行追踪时的示例实施例。
在追踪一个或多个目标对象期间,语义主干210可以处理当前查询帧301并使用上述与图2相关的技术生成一个或多个分割掩码303。融合引擎212可以基于从语义主干210提取的特征生成融合特征313。所融合的特征313可输出到所述特征嵌入引擎216,所述特征嵌入引擎216可生成包含两个特征映射的键值对317。
场景分割和对象追踪系统300的交叉注意引擎306可以处理来自特征存储器204的键值对,并且所述键值对317为当前查询帧301输出所述特征嵌入引擎216。例如,交叉注意引擎306可以将来自特征存储器204的存储的键值对与从当前查询帧中提取的键值对317进行比较,以生成表示当前查询帧301的前景和背景的组合表示。
如上所述,发明描述的场景分割和目标追踪系统和技术可以通过利用语义场景分割期间确定的特征来执行一个或多个目标对象在一系列帧的目标追踪,从而提供计算效率高的联合场景分割和目标追踪。
例如,由于用于多对象追踪的特性是与所有被追踪的目标对象共享的,因此随着追踪的目标对象越来越多,延迟的增加是最小的。另外,语义分割模型是追踪器的集成模块,在这种情况下,打开追踪功能可以减少延迟的增加。
QualcommPatent|Scenesegmentationandobjecttracking
名为“Scenesegmentationandobjecttracking”的高通专利申请最初在2022年5月提交,并在日前由美国专利商标局公布。
需要注意的是,一般来说,美国专利申请接收审查后,自申请日或优先权日起18个月自动公布或根据申请人要求在申请日起18个月内进行公开。注意,专利申请公开不代表专利获批。在专利申请后,美国专利商标局需要进行实际审查,时间可能在1年至3年不等。







