查看
摄像头定位方法







2023-07-12 18:10:41来源:YiVian
查看
摄像头定位方法
(
所以在名为“Cameralocalization”的专利申请中,
现代摄像头方法通常使用图像检索、特征匹配和基于三维结构的姿势估计,但这需要长期存储大量的场景图像或大量的图像特征,所以不太适合资源受限的设备。微软描述的学习型摄像头定位技术则能够避免存储图像特征或详细的三维点云。
其中,一组稀疏的场景landmark可以编码到一个机器学习模型中,只要场景landmark可见,模型就能在查询图像中检测到它们。这种编码消除了维护图像特征数据库的必要性。在一个示例中,机器学习模型训练成回归场景landmark的方位向量(即便它们不在摄像头的视场内)。预测的场景landmark对应关系可以产生极其准确的姿势估计。
这家公司介绍道,所述摄像头定位学习方法可以保护隐私,低内存占用,并优于现有的无存储姿势回归方法。
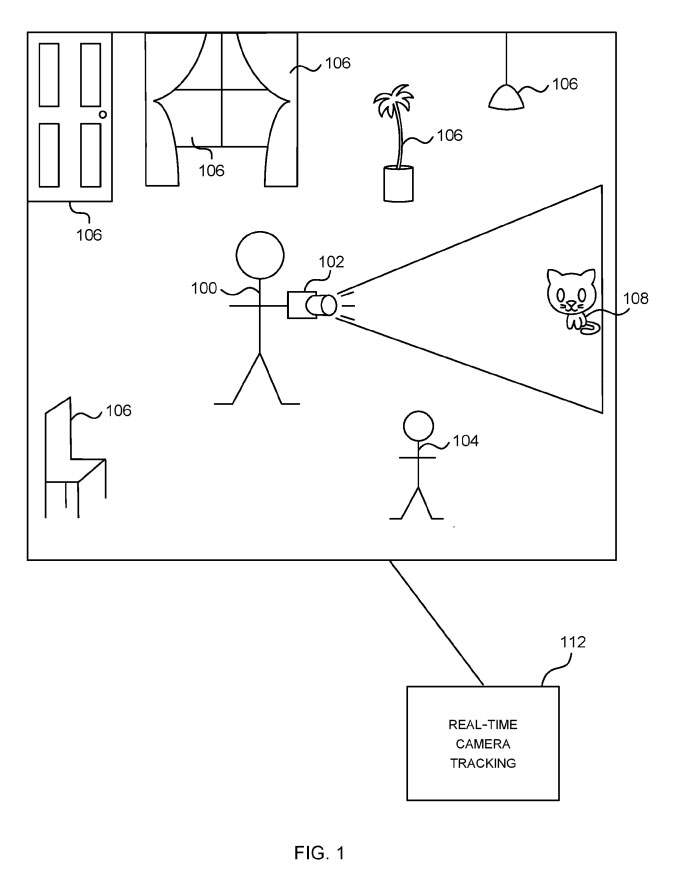
图1是一个人100站在房间里,并拿着一个移动摄像头102。在这个例子中,摄像头同时结合了一个投影仪,而投影仪正在将一只猫108的图像投射到房间里。房间里有各种物体106,如椅子、门、窗户、植物、灯光和另一个人104。
实时摄像头追踪系统112追踪摄像头相对于建筑物内部的三维模型或地图的位置,在追踪过程中,摄像头或实时摄像头追踪系统112无法获得模型或地图,所以安全性得到了提高。实时摄像头追踪系统112使用关于场景的信息,而信息先前已编码到机器学习模型中。
实时摄像头追踪系统112的输出可以由混合现实或其他应用所使用。
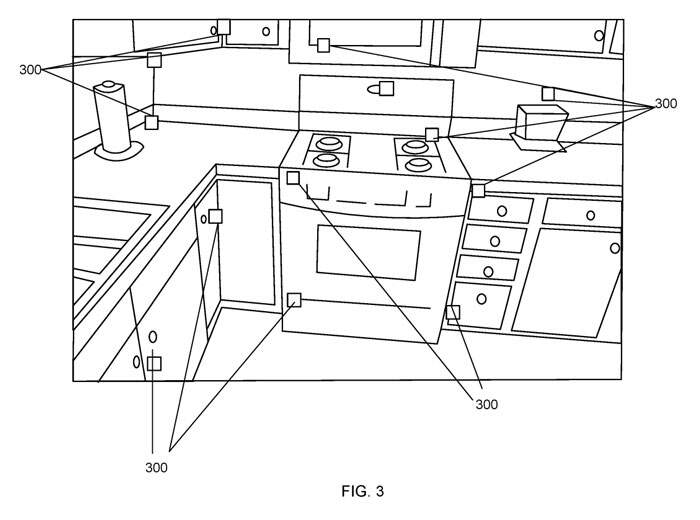
图2是一个建筑物的楼层200的平面图。一个手持移动摄像头204的人202正在移动,如虚线箭头208所示。该人沿着走廊206走过房间和家具210。实时摄像头追踪系统112能够在移动过程中使用经过训练的机器学习模型来追踪移动摄像头204的位置。
实时摄像头追踪系统112使用对摄像头所处场景中预先指定的三维场景landmark的信息进行编码的机器学习模型。
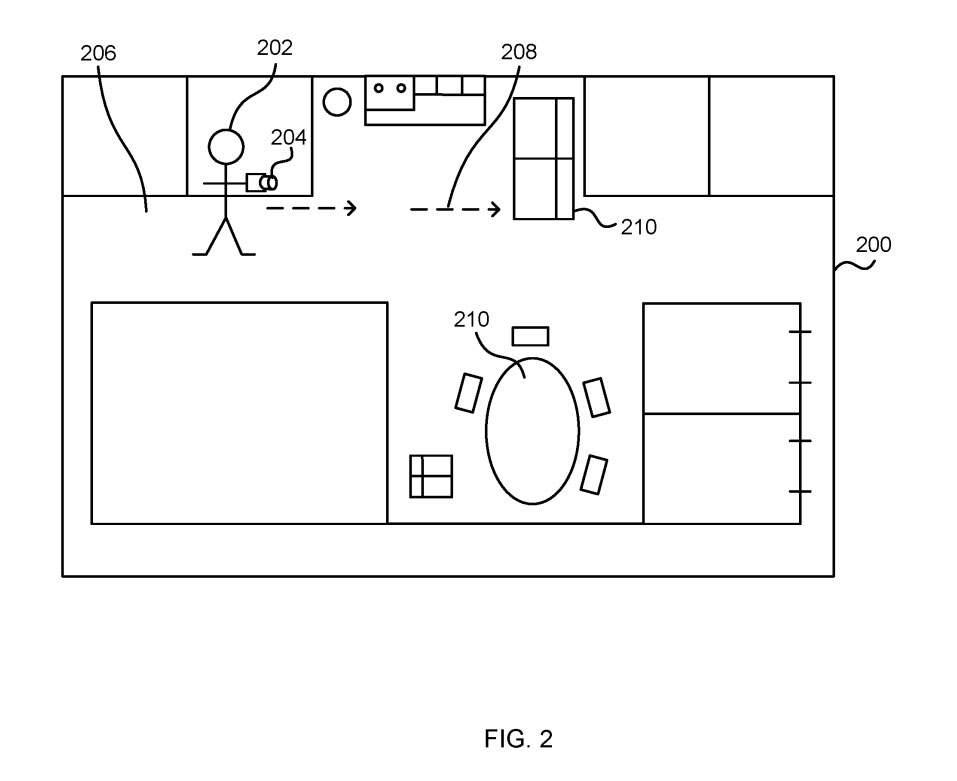
图3是一张查询图像的示意图,显示了机器学习模型在查询图像中检测到的场景landmark300。查询图像是来自摄像头的图像,它输入到一个或两个机器学习模型中。在图3的例子中,查询图像描述了一个家庭厨房的内部,多个预先指定的三维场景landmark的二维位置显示为小矩形。
使用机器学习模型对预先指定的三维场景landmark的信息进行编码,这可以保护隐私,并且由于不需要存储视觉信息,因此需要低内存占用率。机器学习模型建立了二维到三维的对应关系,反过来,可以使用已知的传统技术来稳健地估计摄像头的姿势。
在不同的例子中,可以有一个检测3D场景landmark的第一机器学习模型,即对输入图像中landmark的2D坐标进行回归。
在第一组称为场景landmark检测器(SLD)的实施例中,机器学习模型训练成解决识别图像中描绘三维场景landmark的二维位置的任务。摄像头的内在因素已知,因此二维检测可以转化为三维方位向量或射线。
在第二组称为神经方位估计(NBE)的实施例中,一个不同的机器学习模型训练成直接预测摄像头坐标中的三维场景landmark的三维方位向量。使用SLD,只检测在摄像头视场中可见的三维场景landmark。相比之下,用NBE预测所有landmark的方位。所以即便三维场景landmark被遮挡或在摄像头的视场之外,其都能进行预测。
现在参照图4来描述第一组和第二组实施例。
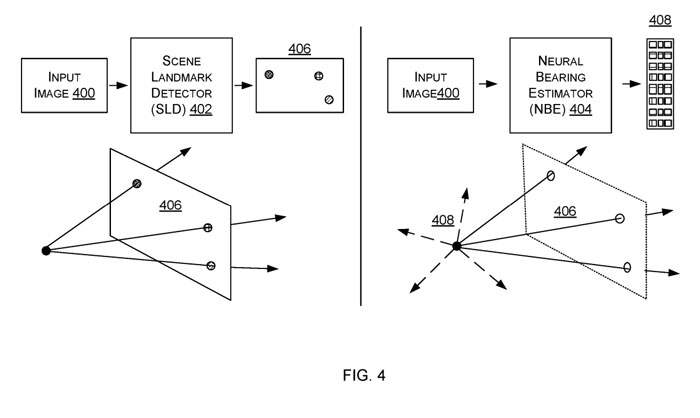
图4是检测描述三维场景landmark的二维图像位置的示意图,它同时是预测三维方位矢量的示意图。图4的左侧显示了场景landmark检测器402,这是一个机器学习模型。来
自摄像头的输入图像400输入到场景landmark检测器402。场景landmark检测器计算输入图像中的二维位置(在图4中显示为406),而所述位置被预测为描述预先指定的三维场景landmark中的单个位置。三维方位矢量可选择从摄像头开始计算,并通过二维位置延伸,如图4左手边的下半部分所示。
为了产生训练数据以训练机器学习模型,来自运动的结构被应用于场景的映射图像,以选择一组突出的三维场景landmark并,自动产生训练结构所需的训练数据。
与人类姿势估计不同的是,在人类姿势估计中,大多数landmark都可见,而大多数场景landmark都不可见,因为视场有限,场景landmark的数量稀少。
这一挑战可以通过学习一个称为神经方位估计器(NBE)的机器学习模型来缓解。其中,所述模型直接回归摄像头坐标系中场景landmark的三维方位向量。三维方位向量是一个以摄像头为起点的向量,指向预先指定的三维场景landmark之一。NBE在学习预测场景landmark的方向向量的同时,它会学习一个全局性的场景表征,即便它们不可见。
图4显示了神经方位估计器404,它是一个机器学习模型。来自摄像头的输入图像400输入到神经方位估计器404,神经方位估计器预测多个三维方位向量408。三维方位矢量源自照摄像头,其中一些通过输入图像400指向输入图像中描绘的三维场景landmark。
其他的三维方位矢量在其他方向指向输入图像中没有描述的三维场景landmark。通过这种方式,即使三维场景landmark在摄像头的视场之外,摄像头姿势追踪的准确性都会非常高。
在例子中,场景landmark检测器402和NBE404被结合起来进行全姿态估计。
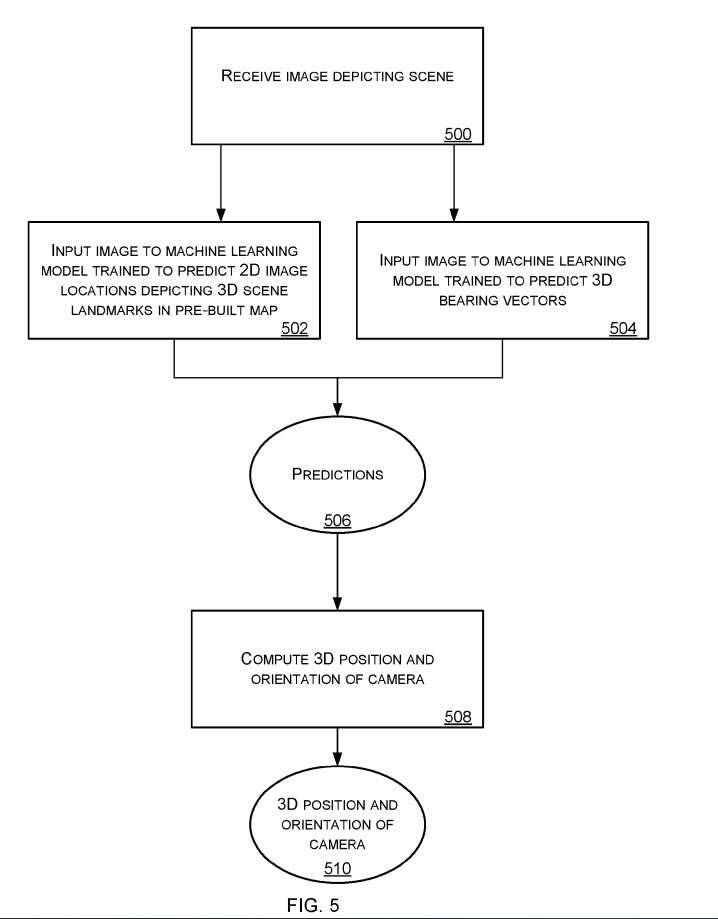
图5是计算摄像头的三维位置和方向的方法的流程图。图5的方法由图1的实时摄像头追踪系统112执行。
参照图5,不同实施例提供了一种在场景内进行摄像头定位的方法。接收摄像头拍摄的场景图像500,并将其输入给机器学习模型502、504。其中,模型已针对特定场景进行训练,以检测多个三维场景landmark。
机器学习模型输出多个预测值506,每个预测值包括:图像中的二维位置或三维方位矢量。
利用预测结果,计算出摄像头在预先建立的场景地图中的位置和方向的估计值508。从预测中计算摄像头的位置和方向的估计的方法的包括使用几何学和关于摄像头参数的信息。
与其他储存场景图像和视频的方法相比,所述方法可以提升安全度。因为在所述方法中,场景的图像和视频没有存储,因此不容易被恶意的一方访问。通常情况下,现场的图像和视频是保密的。
微软指出,所述方法适合在资源有限的设备使用,因为与其他方法相比,所述方法使用的内存很低。一旦经过训练,机器学习模型本身是紧凑的,与存储场景的视频和图像相比,它的内存需求相对较低。
另外,所述方法非常准确,并优于其他无存储的姿态回归方法。所述方法甚至在一个或多个landmark由于被遮挡或在摄像头视场之外的情况下都能发挥作用,并且通过这种方式提高了准确性。
在一个例子中,摄像头是一个在场景中移动的移动摄像头。移动摄像头的定位要比静态摄像头的定位复杂得多,但所述方法对移动摄像头的定位或静态摄像头的定位都非常有效,并且可以实时操作。
在一个例子中,机器学习模型配置为输出预测,并且方法进一步包括将图像输入到第二机器学习模型,而第二机器学习模型配置为输出第二预测作为3D方位矢量。通过这种方式,可以并行使用两个不同的机器学习模型,以提高摄像头定位的准确性和/或稳健性。
在并行使用两个不同的机器学习模型的情况下,模型的输出合并,合并后的输出用来计算摄像头定位。预测的二维位置和预测的三维方位向量中,与同一三维场景landmark有关的一对被确定。在使用预测值计算摄像头的位置和方向的估计值之前,从这些对中丢弃预测的三维方位矢量。
这种方式可以提高准确性,因为预测的二维位置比预测的三维方位矢量更准确,预测的二维位置通常与图像中描绘的三维场景landmark有关,而不是被遮挡或在摄像头视场之外的三维场景landmark。
最好是预先指定的三维landmark的数量少于250个。由于landmark的数量少,在资源有限的设备上使用的存储容量同样可以很低(即机器学习模型的大小很低)。
三维landmark是通过在场景中选择指定数量的三维点来自动确定。这种三维点最稳健、可重复检测、具有独特的外观和可推广。以这种方式选择三维场景landmark可以提高方法的准确性和/或稳健性。
由于场景中的对象可能会移动,场景中的环境光线可能会随着时间的推移而变化,因此选择稳健、可重复检测、外观独特和可推广的三维场景landmark是有益的。
在一个例子中,机器学习模型包括一个卷积神经网络。其中,所述网络已经用监督学习法进行了训练,以预测图像中3Dlandmark的2D位置。使用卷积神经网络特别有效,并提供了一个适合于资源有限的设备的紧凑模型。
机器学习模型可以使用多个多层感知器计算三维方位向量,每个三维landmark有一个多层感知器。因此,所述架构是紧凑的,很适合预测三维方位向量。
机器学习模型是使用训练数据进行训练的,数据包括观察到的场景视频,并表现出外观、光照和几何变化。通过在训练数据中加入多样性,特别是外观、光照和几何变化,得到的模型在实践中特别有效。
一个实施例中,对描绘场景的图像或视频进行对象识别,事先自动选择预先指定的三维场景landmark,并使用规则将三维场景landmark放置在根据规则可能是静态的已识别对象上。使用这种类型的程序来自动选择landmark可以提高精确度,因为所产生的三维场景landmark是静态的。
另外,响应场景中相应图案的消失而移除预先指定的三维场景landmark之一;或响应场景中出现的新突出对象而添加预先指定的三维场景landmark;以及重新训练机器学习模型。通过令方法能够应对场景的变化,可以实现了对场景随时间的变化具有鲁棒性的摄像头定位方法。
在不同的例子中,机器学习模型包括使用来自多个场景的数据训练的第一个神经网络,神经网络馈送到额外的神经网络层。通过使用具有主干的神经网络结构,然后以这种方式使用额外的场景特定层,结果是一个更紧凑的模型,而不是为场景的不同部分使用单独的模型。因此可以节省资源。
在不同的例子中,场景是一个大场景,分为多个重叠的子区域,其中方法包括为每个子区域使用不同的多个三维场景landmark,为每个子区域使用不同的机器学习模型,使用分类器将图像分类到子区域之一,并将图像输入到与该子区域相关的机器学习模型。这种方法对大场景特别有效,如有几个房间的家庭住宅。
在不同的实施例中,有一种用于检测图像或视频中的三维场景landmark的方法。由摄像头拍摄的场景图像输入到机器学习模型,以检测多个三维场景landmark。三维场景landmark是在预先建立的场景地图中预先指定的。
机器学习模型输出多个预测,每个预测包括:图像中的二维位置或三维方位矢量。
使用机器学习模型从场景的图像中预测预先指定的三维场景landmark,这使得设备能够以非常规的方式操作,以实现摄像头的定位。
微软专利申请最初在2022年2月提交,并在日前由美国专利商标局公布。
原文链接:https://news.nweon.com/110199
来源媒体:YiVian







