





查看
低频增强
(
在一个实施例中,音频系统包括组织换能器传感器。组织换能器包括空气传导换能器(即扬声器),空气传导换能器耦合到一个或多个组织换能器(例如软骨传导换能器和/或骨传导换能器),并用于驱动一个或更多个组织换能器。由空气传导换能器产生的背压用于驱动一个或多个组织换能器振动用户耳朵的至少一个组织,以形成一组空气传播的声压波。
一个或多个组织换能器配置为将声信号(即背压)转换为用户耳朵的至少一个组织的机械振动,从而产生空气传播的声压波。空气传导换能器配置为既产生通过空气传播的声音,又产生通过与一个或多个组织换能器的直接接触机械耦合到用户耳朵的振动。具有空气耦合组织换能器的音频系统配置为提供空气传导换能器的低频增强(例如低于1000Hz的频率)。
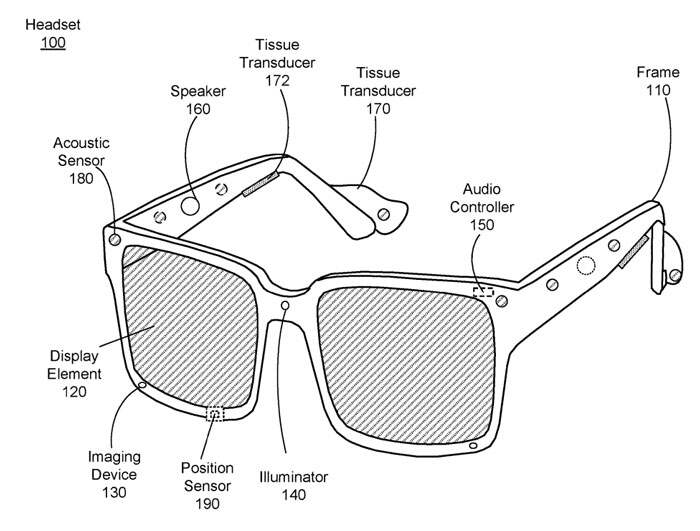
图1示出了一个头显实施例。音频系统向佩戴头显100的用户提供音频内容。音频系统包括换能器阵列、传感器阵列和音频控制器150。
换能器阵列向用户呈现声音。换能器阵列包括多个换能器。换能器可以是扬声器160、组织换能器170或组织换能器172(例如骨传导换能器或软骨传导换能器)。组织换能器170、172耦合到用户的头部并且直接振动用户的至少一个组织(例如骨骼和/或软骨)以产生声音。
扬声器160可以产生通过外壳朝向组织换能器172(和/或组织换能器170)传播的背压,从而驱动组织换能器172和/或组织换能器170。
在一个或多个实施例中,由扬声器160产生的背压提供给框架110内的音频波导(图1A中未示出),音频波导将背压波引导到位于框架110更远的组织换能器(组织换能器172和/或组织换能器170)。组织换能器172配置为将声学信号(即背压)转换为用户的至少一个组织(例如骨骼和/或软骨)的机械振动,从而产生声压波。
音频控制器150处理来自传感器阵列的声音描述信息。音频控制器150可以包括处理器和非瞬态计算机可读存储介质。音频控制器150可以配置为生成到达方向(DOA)估计,生成声学传递函数,追踪声源的位置,在声源的方向形成波束,对声源进行分类,为扬声器160生成声音滤波器等。
音频系统被完全集成到头显100中。位置传感器190响应于头显100的运动而产生一个或多个测量信号。位置传感器190可以包括惯性测量单元(IMU)。
音频系统可以使用描述头显100的位置信息(例如来自位置传感器190)来更新声源的虚拟位置,使得声源相对于头显100位置锁定。在这种情况下,当用户转动头部时,虚拟源的虚拟位置随着头部移动。
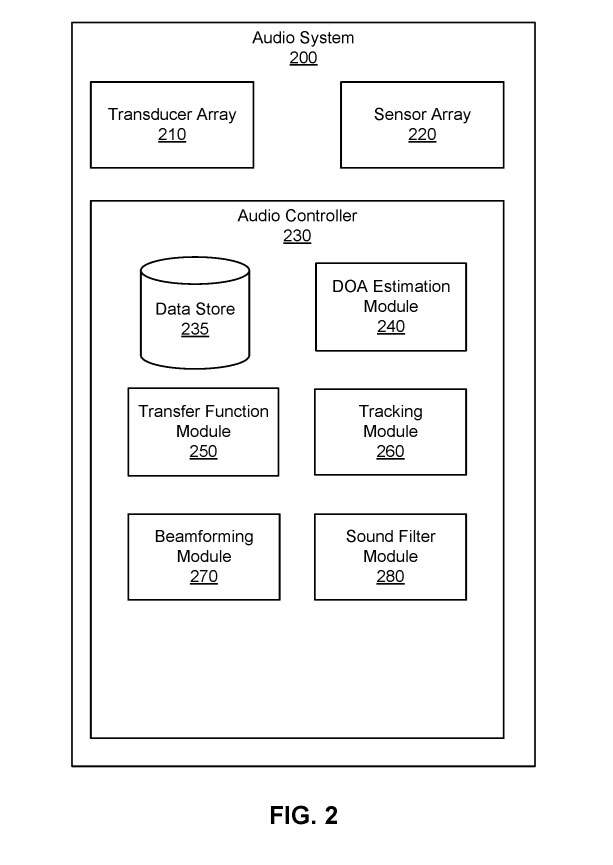
图2是音频系统200的框图。音频系统200为用户生成一个或多个声学传递函数。音频系统200然后可以使用一个或多个声学传递函数来为用户生成音频内容。在图2的实施例中,音频系统200包括换能器阵列210、传感器阵列220和音频控制器230。
在一个实施例中,换能器可以配置为用作骨传导换能器或软骨传导换能器。骨传导换能器通过振动用户头部中的骨/组织来产生声压波。
骨传导换能器从音频控制器230接收振动指令,并基于接收到的指令振动用户头骨的一部分。来自骨传导换能器的振动产生组织传播的声压波,而声压波绕过鼓膜向用户的耳蜗传播。
在一个实施例中,软骨传导换能器通过振动用户耳朵的耳软骨的一个或多个部分来产生声压波。软骨传导换能器可以耦合到头显,并且可以配置为耦合到耳朵软骨的一个或多个部分。例如,软骨传导换能器可以耦合到用户耳朵的耳廓后部。软骨传导换能器可以位于外耳周围沿着耳软骨的任何位置。
振动耳廓软骨的一个或多个部分可能会在耳道外产生空气传播的声压波,引起耳道的一些部分振动,从而在耳道内产生声压波。所产生的声压波沿着耳道向鼓膜传播。
换能器阵列210配置为增强低频,例如低于定义的阈值频率(例如1000Hz)的音频频率。换能器阵列210可以包括至少一个组织换能器和驱动至少一个结构换能器的扬声器。
所述至少一个组织换能器配置为耦合到用户身体的一部分(例如耳朵和/或头骨),并且扬声器耦合到组织换能器。
注意,扬声器产生的高频声压波不会影响组织换能器,即扬声器和组织换能器相对于高频声压波是隔离的。扬声器可以包括具有第一表面和与第一表面相对的第二表面的隔膜。扬声器的第一表面可以配置为生成第一组空气传播的声压波,并且第二表面可以配置为生成背压。
组织换能器由背压驱动以振动至少一个组织以形成第二组声压波。第一组空气传播的声压波和第二组声压波一起形成呈现给用户的音频内容。
传感器阵列220检测传感器阵列220周围的局部区域内的声音。传感器阵列220可以包括多个声学传感器,每个声学传感器检测声波的气压变化,并将检测到的声音转换为电子格式。
音频控制器230控制音频系统200的操作。在图2的实施例中,音频控制器230包括数据存储器235、DOA估计模块240、传递函数模块250、追踪模块260、波束成形模块270和声音滤波器模块280。
音频控制器230控制换能器阵列210的操作,以提供低频增强。音频控制器230可以生成用于换能器阵列210的扬声器的音频指令,指示扬声器生成以生成空气传播声波。空气传播的声波引起背压,背压驱动换能器阵列210的至少一个组织换能器振动用户头部的一部分的至少一种组织,致使至少一个组织产生声压波,而声压波形成用于呈现给用户的音频内容。
另外,音频控制器230可以启动扬声器(例如经由音频指令)以直接产生空气传播的声压波。由扬声器直接产生的空气传播的声压波,以及由至少一个组织换能器产生的声压波一起形成呈现给用户的音频内容。
DOA估计模块240配置为部分地基于来自传感器阵列220的信息来定位局部区域中的声源。DOA估计模块240执行DOA分析以定位局部区域内的一个或多个声源。DOA分析可以包括分析每个声音在传感器阵列220处的强度、频谱和/或到达时间,以确定声音起源的方向。
例如,DOA分析可以设计为接收来自传感器阵列220的输入信号,并将数字信号处理算法应用于输入信号以估计到达方向。
在一个实施例中,DOA估计模块240同时可以确定关于音频系统200在局部区域内的绝对位置的DOA。传感器阵列220的位置可以从外部系统接收。外部系统可以创建局部区域的虚拟模型,在模型中映射局部区域和音频系统200的位置。接收到的位置信息可以包括音频系统200的一些或全部位置和/或方位。DOA估计模块240可以基于接收到的位置信息来更新估计的DOA。
传递函数模块250为音频系统200的用户确定一个或多个HRTF。HRTF表征了耳朵如何从空间中的一个点接收声音。传递函数模块250可以使用校准过程来确定用户的HRTF。传递函数模块250可以向远程系统提供关于用户的信息。
在一个实施例中,用户可以调整隐私设置,以允许或阻止传递功能模块250向任何远程系统提供关于用户的信息。远程系统确定使用例如机器学习为用户定制的一组HRTF,并将该组定制的HRTF提供给音频系统200。
追踪模块260配置为追踪一个或多个声源的位置。追踪模块260可以比较当前DOA估计,并将其与先前DOA估计的存储历史进行比较。在一个实施例中,音频系统200可以周期性地重新计算DOA估计,例如每秒一次或每毫秒一次。
追踪模块可以将当前DOA估计与先前DOA估计进行比较,并且响应于声源的DOA估计的变化,追踪模块260可以确定声源移动了。追踪模块260可以计算定位方差的估计。定位方差可以用作每次确定运动变化的置信水平。
波束成形模块270配置为处理一个或多个ATF,以选择性地强调来自特定区域内的声源的声音,同时去强调来自其他区域的声音。在分析由传感器阵列220检测到的声音时,波束成形模块270可以组合来自不同声学传感器的信息,以强调与局部区域的特定区域相关联的声音,同时淡化来自区域外部的声音。
波束成形模块270可以基于例如来自DOA估计模块240和追踪模块260的不同DOA估计,将与来自特定声源的声音相关联的音频信号与本地区域中的其他声源隔离。波束成形模块270因此可以选择性地分析局部区域中的离散声源。
声音滤波器模块280确定用于换能器阵列210的声音滤波器。声音滤波器使得音频内容被空间化,使得音频内容看起来源自目标区域。声音滤波器模块280可以使用HRTF和/或声学参数来生成声音滤波器。
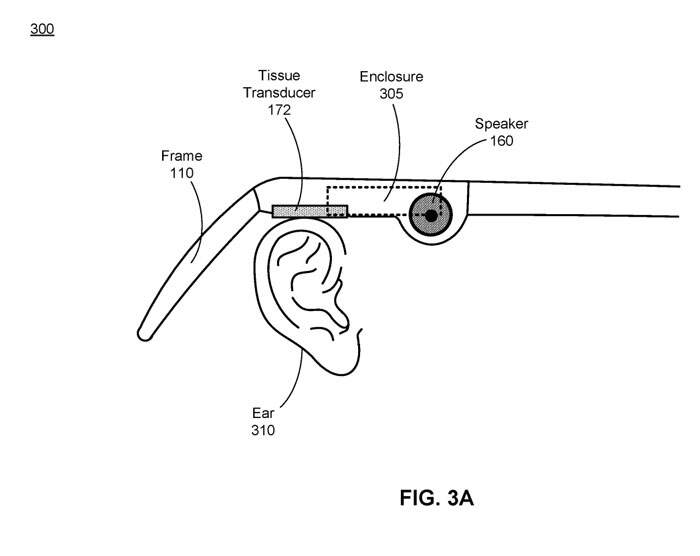
图3A示出了音频系统实现300,所述音频系统包括配置为驱动组织换能器172的扬声器160。由扬声器160产生的空气传播的声压波可以通过耳朵310的耳道中的空气传播到鼓膜,在鼓膜处空气传播的声波被用户感知为声音。
组织换能器172实现为连接到用户组织(例如,耳廓或耳后骨)的接触垫(即接触元件),其中接触垫在被背压驱动时使组织振动。
在一个实施例中,组织换能器172实现为直接耦合到例如耳朵310的耳廓的软骨传导换能器。在这种情况下,软骨传导换能器由扬声器160产生的外壳305中的背压驱动,以振动耳廓,导致耳廓产生空气传播的声压波。
在其他实施例中,组织换能器172实现为骨传导换能器,骨传导换能器耦合到耳朵310后面的骨的至少一部分。骨传导换能器可以由扬声器160产生的外壳305中的背压驱动,以振动骨骼,从而使骨骼产生骨载声压波。
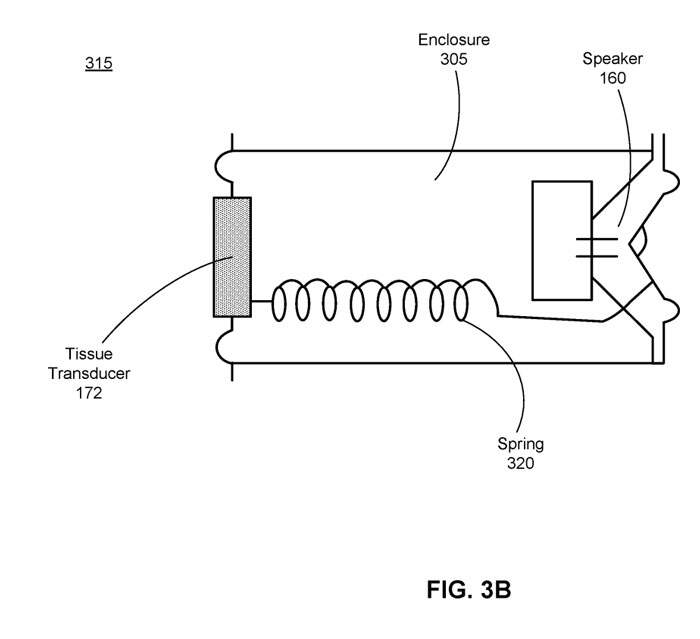
图3B示出了音频系统实现模型315。模型315包括外壳305(即密封容积)内的扬声器160,外壳305经由弹簧320耦合到组织换能器172。弹簧320模拟由扬声器160发起的外壳305内的背压空气的运动,以在外壳305内形成背压Pb。
背压然后驱动组织换能器172振动用户的组织(例如耳后的耳廓或骨头),从而产生声压波。外壳305内的空气体积的刚度和系统部件的质量可以调谐以在低频(例如低于1000Hz的频率)下最大化效率。

图3C示出了音频系统的另一示例实现350。扬声器160产生空气传播的声压波以及用于驱动组织换能器172的背压。扬声器160位于外壳355内。扬声器160可以基于例如来自音频控制器150(图3C中未示出)的第一音频指令来生成引起外壳355内的背压Pb的空气传播声波。
扬声器160可以包括具有第一表面362和与第一表面364相对的第二表面364的隔膜360。第一表面362可以产生空气传播的声压波,所述空气传播的声学压力波例如在外壳355的外部并且朝向鼓膜传播到耳朵310的耳道,在鼓膜处空气传播的声波被用户感知为声音。第二表面364可以在外壳355内产生后体积空气的运动,以在外壳355中形成背压Pb。
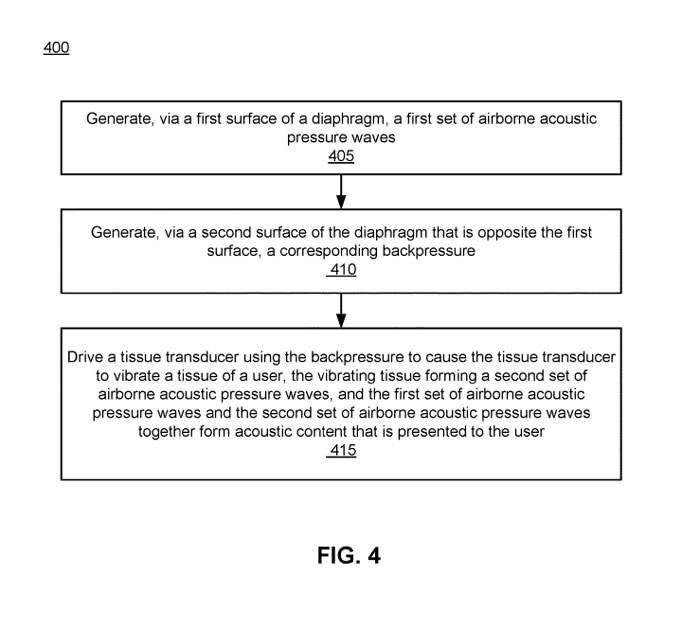
图4示出了音频系统生成音频内容的过程400。
在405,音频系统经由膜片的第一表面生成405第一组空气传播的声压波。
在410,音频系统经由隔膜与第一表面相对的第二表面产生相应的背压。音频系统可以在包围隔膜和组织换能器的至少一部分的外壳内产生相应的背压,并且组织换能器耦合到用户身体一部分的组织(例如耳廓或耳后骨)。或者,音频系统可以在外壳中产生相应的背压。
在415,音频系统使用背压驱动组织换能器,以使组织换能器振动用户的组织,振动的组织形成第二组声压波,并且第一组空气传播的声压波和第二组声学压力波一起形成呈现给用户的音频内容。
在一个实施例中,音频系统通过相应的背压驱动组织换能器以振动组织,从而使组织产生第二组声压波。在另一个实施例中,音频系统通过相应的背压驱动组织换能器的柔性中空部件以振动组织,从而使组织产生第二组声压波。
MetaPatent|Audiosystemwithtissuetransducerdrivenbyairconductiontransducer
名为“Audiosystemwithtissuetransducerdrivenbyairconductiontransducer”的Meta专利申请最初在2021年9月提交,并在日前由美国专利商标局公布。







