





查看
将捕获的视场裁剪至或调整至对应的预期用户视场
(
所以在名为“Systemfordetermininganexpectedfieldofview”的专利申请中,Meta就提出了一种相关的解决方案:确定所需视场的定向定向和/或位置数据,然后将捕获的视场裁剪至对应的预期用户视场。
在一个示例中,图像捕获组件可以捕获比所需更宽或更大的视场,这时系统可以通过测量组件确定相关的定向和/或位置数据108,并由裁剪组件裁剪至或调整至对应的用户视场。
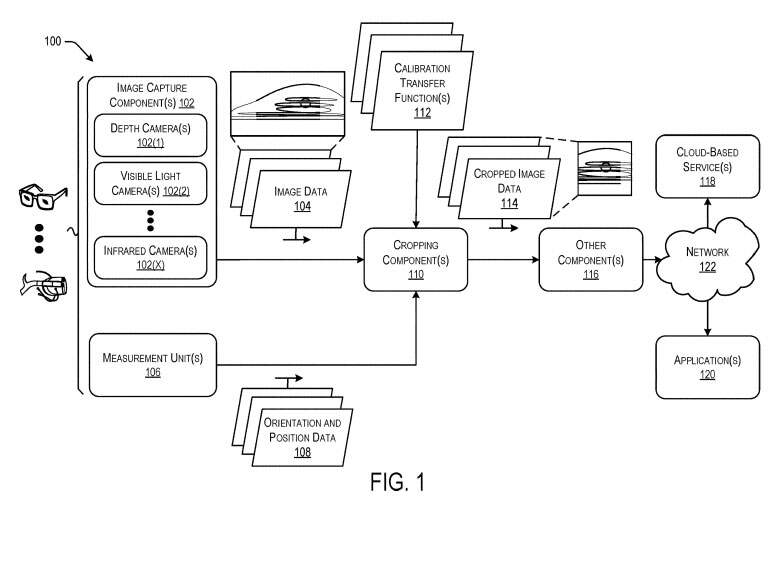
图1是示例性图像捕获系统100的框图。图像捕获系统100可以包括一个或多个图像捕获组件102,以生成表示物理环境的图像数据104。
图像捕获系统100同时包括一个或多个测量组件106,以生成与包括图像捕获系统的电子设备相关联的定向和/或位置数据108。测量组件106可以与特定的图像捕获组件对齐或定位在其附近,以便相对于图像捕获组件定位方位和/或位置数据。
图像捕获系统同时包括裁剪组件110,裁剪组件可以分别从图像捕捉设备102和测量单元106接收图像数据104,以及方位和/或位置数据108。裁剪组件110可以配置为解析或以其他方式分析图像数据(例如相对于当前帧的前一帧),并识别图像数据104内的目标对象或区域。
裁剪组件110然后可以调整与图像数据104相关联的视场或视场区域的位置,以包括或以其他方式围绕目标对象或区域居中或与之对齐。在一个实施例中,裁剪组件110可以利用一个或多个机器学习模型或网络来识别图像数据104的前一帧内的目标对象或区域。在这种情况下,裁剪组件110然后可以识别当前帧内的目标对象和区域,并相应地裁剪图像数据104。
在一个实施例中,图像捕获设备可以包括扩展的垂直视场,并且电子设备可以至少部分地基于可穿戴电子设备IMU接收的定向和移动数据,调整图像数据的垂直裁剪。例如,如果IMU数据指示用户的头部向下倾斜,则电子设备可以基于比IMU数据所示视场低的视场来裁剪图像数据。
在一个实施例中,预定垂直距离可以基于IMU数据指示用户向上或向下倾斜头部的程度而变化。例如,头部的向上或向下倾斜越大,预定垂直距离从IMU数据指示的位置变化得越大。在一个示例中,可以使用一个或多个机器学习模型或网络来训练或学习预定垂直距离的值。在其他示例中,可以使用可穿戴电子设备上的注视检测系统来确定用户的眼睛的视场,并且可以使用检测到的眼睛的视场,或注视以及IMU数据来确定眼睛倾斜的附加调整。
一旦裁剪组件110输出了裁剪的图像数据114,则电子设备的其他组件116可以利用裁剪的图像图像数据114。裁剪的图像数据114同时可以经由一个或多个网络122发送到由基于云的服务118和/或伴随应用120。在所述示例中,通过由裁剪组件110在电子设备端执行裁剪,可以减少带宽和网络资源消耗。
例如,图像捕获组件102可以捕获比所需更宽或更大的视场,并且传统系统会将更大的原始图像数据传输或流式传输到远程系统以进行处理。但通过网络122传输或流传输之前将图像数据104裁剪或以其他方式减少到期望的大小和内容,可以显著减少网络资源消耗和与之相关的成本。
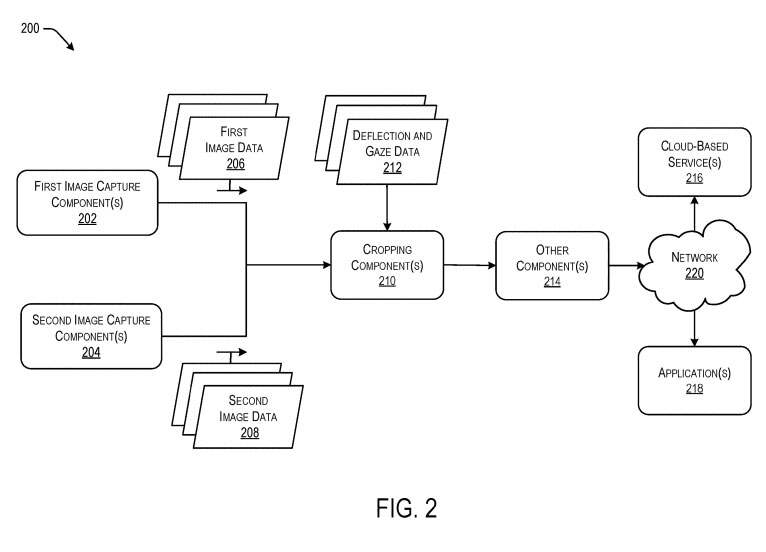
图2是图像捕获系统200的另一示例框图。可穿戴电子设备可以配备有立体图像捕获系统200,所述立体图像捕获设备200包括至少第一图像捕获组件202和第二图像捕获组件204。
第一图像捕获组件202和第二图像捕获组件204可能会在使用期间垂直和/或水平地错位。例如,用户可以具有两个高度略有不同的耳朵,并导致可穿戴电子设备相对于彼此和与可穿戴电子装置的框架相关联的一个或多个轴形成微小角度。
在当前示例中,第一图像捕获组件202可以生成与系统200周围的物理环境相关联的第一图像数据206,第二图像捕获组件204可以生成与物理环境相关的第二图像数据208。如上所述,系统200可以包括裁剪组件210,其接收第一图像数据206和第二图像数据208。
裁剪组件210可以配置为解析或以其他方式分析第一图像数据206和第二图像数据208。然后,裁剪组件210可以调整与第一图像数据206和第二图像数据208相关联的视场位置,以包括或以其他方式围绕目标对象或区域彼此居中或对齐。再次,裁剪组件210可以利用一个或多个机器学习模型或网络来识别目标对象或区域,或者以其他方式对齐第一图像数据206和第二图像数据208。
在所述示例中,用户可以执行初始化或设置过程,使得图像捕获系统200可以确定一个或多个偏转数据和/或注视数据。例如,与由可穿戴电子设备和/或相关的便携式电子设备托管的系统200相关联的应用218可以使得用户或佩戴者执行设置或初始化。例如,可以指示用户站在镜子前面,头部以各种角度定位。
第一图像捕获组件202和第二图像捕获组件204可以在初始化过程期间生成初始化图像数据,例如第一图像数据206和第二数据208。裁剪组件210和/或另一系统可以确定与用户的个人角色和面部特征相关联的偏转数据和/或注视数据212。然后可以存储偏转数据和/或注视数据212,使得裁剪组件210可以使用偏转数据和(或)注视数据212裁剪第一图像数据206和第二图像数据208,并生成表示用户视场的输出图像数据。
然后,输出图像数据可以在系统200上使用,例如经由无线网络接口发送、传输或以其他方式流式传输到其他设备以供进一步处理。
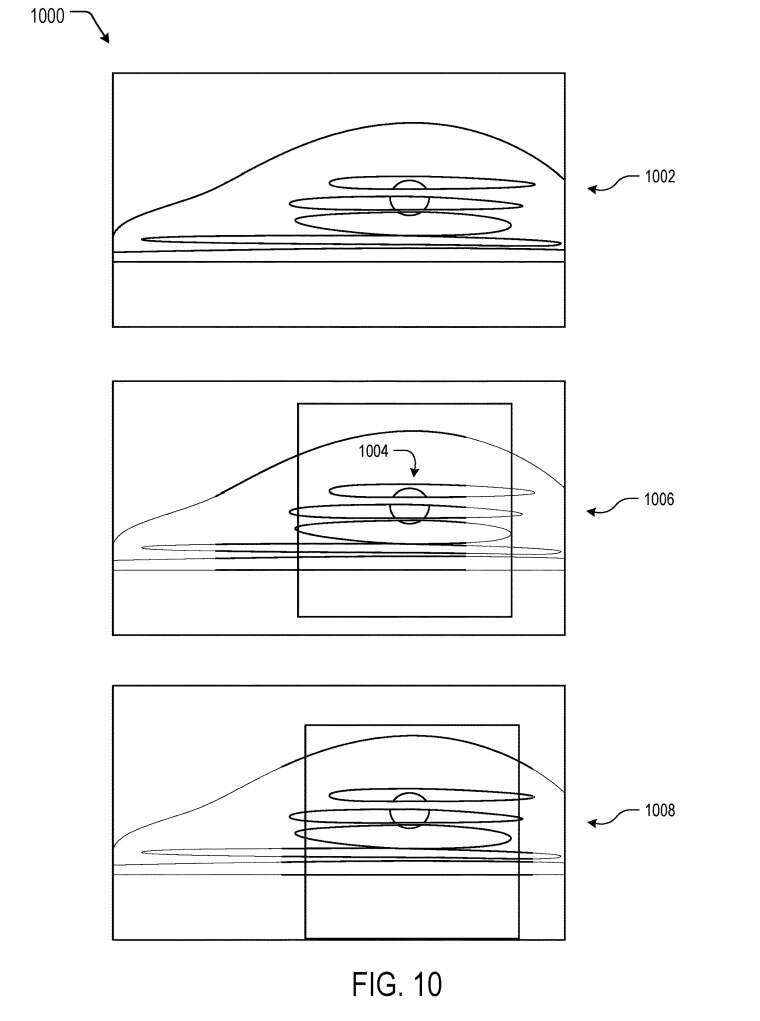
图10是根据一个或多个示例的与图像捕获系统相关联的图像数据1000的示例裁剪图示。系统可以配备有图像捕获组件,其具有比系统输出的图像数据更大的视场和/或分辨率。由图像捕获组件捕获的原始图像数据通常示为1002。
在一个实施例中,系统可以基于检测到的目标1004裁剪或框定图像数据1000。系统可以通过裁剪图像数据1000来生成输出图像数据,如1006所示。以这种方式,目标1004位于输出图像数据的中心。如上所述,系统同时可以基于方位和位置数据来调整图像数据1000的裁剪或成帧。在所示示例中,用户可以稍微向下看。因此,系统可以向下调整垂直裁剪或框架的位置,如1008所示,以与用户的可能视场对齐。
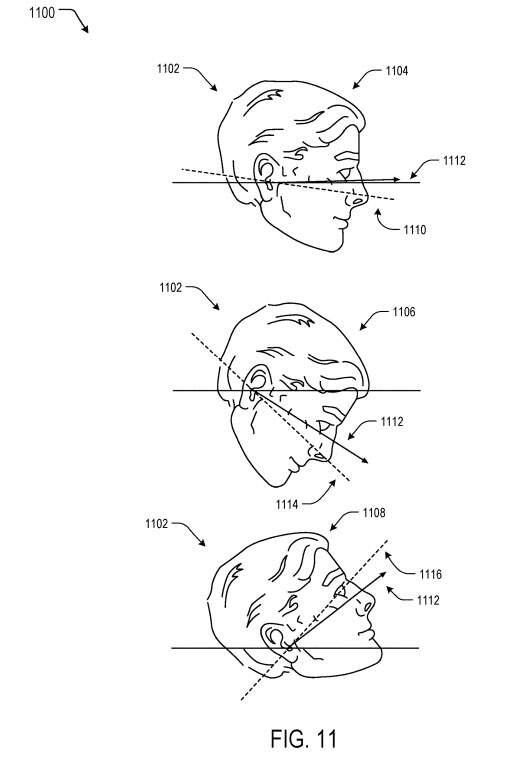
图11是示出根据一个或多个示例的基于头部位置的示例性视场调整示意图1100。在当前示例中,用户的头部1102显示在不同的位置1104–1108。例如,第一位置1104基本上直立,第二位置1106鼻子向下倾斜,第三位置1108鼻子向上倾斜。在第一位置1104中,用户的视场1110与图像捕获系统的视场1112基本对齐。
然而,在第二位置1106中,用户的视场1114低于图像捕获系统的视场1112,因为当用户向下倾斜头部时,用户可以进一步向下调整眼睛。类似地,在第三位置1108中,用户的视场1116高于图像捕获系统的视场1112,因为即使当用户向上仰起头,用户都可以继续向上调整他们的眼睛。
在其他示例中,用户的注视方向和视场可以基本上与用户的头距相同、高于或低于用户的头间距。
如上所述,系统可以初始化或训练为基于用户的个人特征来调整图像捕获系统的视场,或者系统可以基于所示位置1104–1108以及其他位置的平均用户来对视场进行调整。例如,进行不同程度的向前或向后倾斜,并结合俯仰的额外旋转等。
以这种方式,由可穿戴电子设备捕获的图像和视频数据可以对应于预期的用户视场。
MetaPatent|Systemfordetermininganexpectedfieldofview
名为“Systemfordetermininganexpectedfieldofview”的Meta专利申请最初在2021年6月提交,并在日前由美国专利商标局公布。







