查看
苏黎世联邦理工学院,图宾根大学和马克斯·普朗克智能系统研究所
(
在日前公布的论文《gDNA:TowardsGenerativeDetailedNeuralAvatars》中,由黎世联邦理工学院,图宾根大学和马克斯·普朗克智能系统研究所组成的研究人员希望能够轻松创建详细的虚拟数字人。






2022-04-27 18:10:36来源:YiVian
查看
苏黎世联邦理工学院,图宾根大学和马克斯·普朗克智能系统研究所
(
在日前公布的论文《gDNA:TowardsGenerativeDetailedNeuralAvatars》中,由黎世联邦理工学院,图宾根大学和马克斯·普朗克智能系统研究所组成的研究人员希望能够轻松创建详细的虚拟数字人。
团队的目标是通过学习一个generativemodelofpeople模型,从而帮助社区广泛访问3D虚拟数字人。为了实现这一目标,研究人员提出了一种方法,而且它可以:
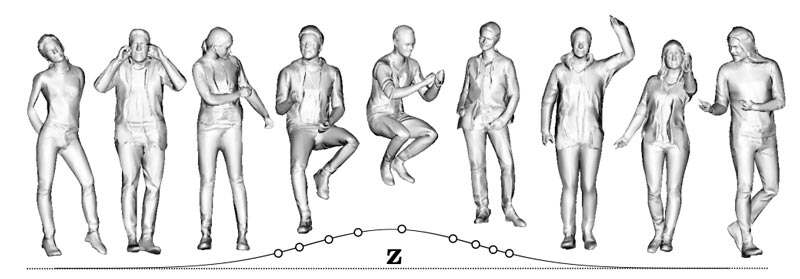
三维刚体对象的GenerativeModeling正在快速发展,但由于服装、其拓扑结构和姿势驱动的变形之间的复杂交互,为穿衣人及其关节建模非常困难。有研究利用神经内隐曲面为singlesubject学习高质量的关节数字人,但它们并非生成性,即无法合成新的人类特征和形状。现有的服装生成模型通过预测人体网格的位移(CAPE),或通过在T-posed身体拖动隐式服装表示(SMPLicit),并依靠SMPL学习的蒙皮进行重摆来增强SMPL。
团队表明,特征、形状、清晰度和服装的整体建模可以提高数字人的逼真度和动画效果,并提高3D扫描的准确度。为了实现详细神经数字人的完全GenerativeModeling,由黎世联邦理工学院,图宾根大学和马克斯·普朗克智能系统研究所组成的研究人员提出了gDNA。
这是一种合成新颖人体形状的3D曲面的方法,可允许控制服装样式和姿势,并生成服装的真实高频细节。
为了利用原始(姿势)3D扫描,团队构建了一个multi-subject隐式生成表示,并将SNARF作为基础。SNARF这种方放可以很好地推广到不可见姿势。但SNARF需要一个singlesubject的多个姿势进行训练。相比之下,团队的multi-subject方法可以从众多不同subject的极少数姿势扫描中学习。
这是通过增加一个latent空间来实现,以便有条件地为穿衣人生成形状和蒙皮权重。另外,学习的扭曲field使用相同的蒙皮field产生精确的变形。
服装褶皱是由一个随机过程产生。为了捕获所述效果,团队提出了一种通过对抗性损失学习3D服装细节underlyingstatistics的方法。以前基于网格的方法在UV空间中formulate,但由于缺乏网格连通性,这不直接适用于隐式曲面。为了学习高频细节,研究人员首先根据粗糙的形状特征预测三维法向field。为了将对抗性损失反向传播到3D法线field,他们通过使用隐式曲面渲染器增强正向蒙皮来建立3D-2D对应。结果发现,对抗性训练可以显著提高3D几何细节的逼真度。
团队仅通过姿势扫描进行训练,并证明所述方法可以在姿势控制下生成大量具有详细皱纹的3D服装人体形状。生成的样本可以通过学习的蒙皮权重进行重置。实验显示,gDNA的表现明显优于基线。另外,gDNA可以用于3D扫描的拟合和重动画,并且优于最新技术SOTA。
具体方法
研究人员希望构建一个可以生成各种不同特征的3D穿衣人类,并以任意姿势呈现精细几何细节的模型。相关模型是从一组稀疏的静态扫描中学习,不需要假设曲面对应。
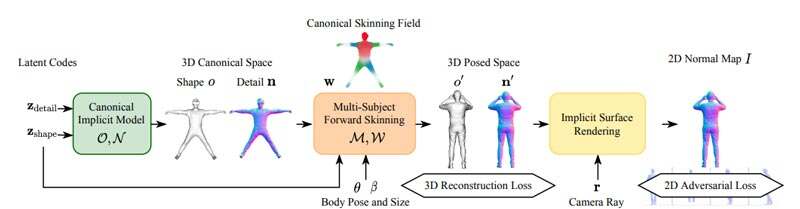
方法如图2所示。首先,团队formulate了一个独立于姿势和体型的穿衣人体形状的canonicalrepresentation。其次,为了从每个subject的极少数姿势扫描中学习标准形状和变形特性,通过形状、关节和服装的latent空间将single-subject可微分正向蒙皮方法扩展到multiplesubject。最后,为了学习丰富而随机的几何细节,通过2D对抗损失公式学习了详细的3D法线field。为了实现这一点,研究人员使用隐式曲面渲染器扩展了正向蒙皮模块。
1.1粗糙形状
将canonicalspace中的形状建模为:
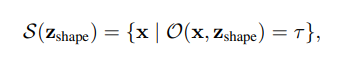
其中其中O是预测canonicalspace中任意3D点x的占用概率的神经网络。

占用网络同时为每个曲面点输出尺寸为Lf的特征向量f。这个特征携带粗略形状信息,并用于预测细节。研究人员将一个基于3DCNN的特征生成器和一个局部条件化的MLP组合到模型O中。
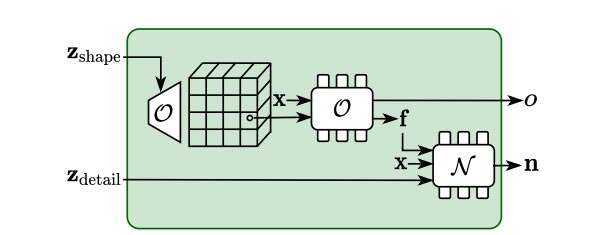
如图3所示,基于3D样式的生成器首先通过自适应实例规范化生成一个以Zshape为条件的3D特征volume。通过特征volume的三线性采样,并将特征和3D坐标输入MLP,可获得最终占用率
1.2详细的曲面法线
学习multiplesubject和服装类型的占用field,以及精确和详细的法线是一项挑战。类似于多边形网格的法线贴图,研究人员通过canonical3D空间中的法线来建模曲面细节。这种曲面法线可以用隐式函数的梯度表示,但会导致相当大的计算复杂性。所以,他们使用MLP来预测曲面法线。然而,由于隐式曲面没有连通性的概念,团队提出了一种几何感知方法来连接粗糙几何体和详细法线field。更具体地说,利用占用网络中的特征f来对基础形状进行曲面法线预测。研究人员进一步生成了可控细节:
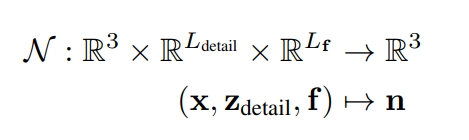
2.1Single-Subject蒙皮表示
为了在可控身体姿势θ中为隐式人体形状设置动画,最近的研究将基于网格的线性混合蒙皮算法推广到神经隐式曲面。每个3D点的骨骼变形建模为一组骨骼变换的加权平均值,每个点的权重由MLP预测。一个关键的区别是:这个蒙皮权重field是在canonicalspace中定义,还是在posedspace中定义。
团队在canonicalspace中定义蒙皮field:
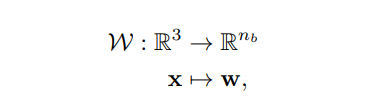
在canonicalspace中定义是可取的,因为蒙皮权重随后与姿势无关,因此更容易学习,并能够推广到out-of-distributionpose。
2.2Multi-Subject蒙皮表示
研究人员将这种正向蒙皮概念扩展到Multi-Subject。由于蒙皮权重是在canonicalspace中定义,因此这个模型可以在多个训练实例上聚合信息。重要的是,这使得能够从multisubject的一个或几个姿势学习蒙皮,而不是要求同一subject的多个姿势。
为了实现这一点,研究人员将来自体型变化β和穿衣人体形状Z的影响解耦,并在body-size-neutral
space中模拟蒙皮field,类似于标准曲面表示。为了捕捉不同的穿衣人形状,团队采用了以下公式:
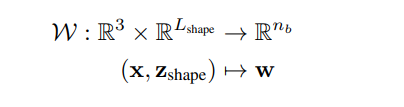
然后,用附加的翘曲field来模拟身体大小的变化。给定β-sizespace中的一个点xˆ,翘曲field通过预测其canonicalcorrespondencex将其映射回平均尺寸:
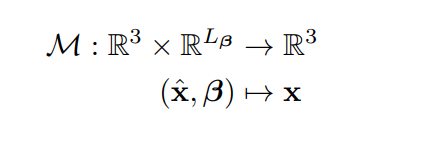
在这个公式中,β类似于SMPL捕捉体型变化,例如身高。因此,canonical形状网络只需要对SMPL之外的其他形状变化进行建模,例如衣服和头发。最终调整大小的标准曲面定义为:
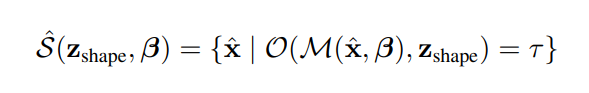
给定目标体姿态θ,β-sizespce中的点xˆ通过以下公式变成posedspacex’:
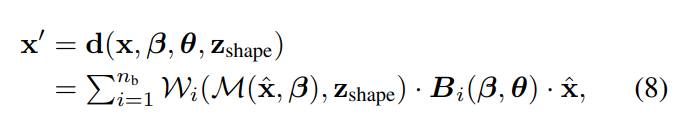
2.3隐式可微正向蒙皮
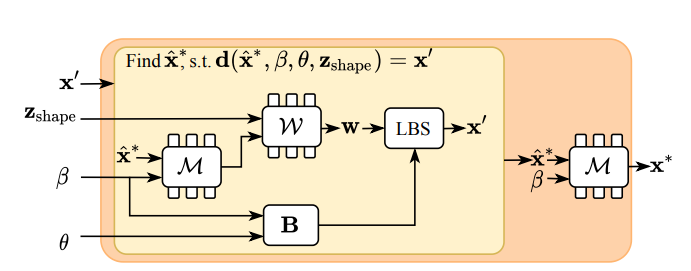
当我们的模型学习canonicalrepresentation时,它的监督是在posedspace中提供。给定一个在posedspace中的点x’,我们需要确定它在canonicalspacex中的对应关系,以便将预测的占有率和法线与groundtruth值进行比较。
首先在resizedcanonicalspace中找到x’对应的xˆ∗,然后映射xˆ∗到canonicalspacex∗。图示可参见图4:
3.隐式曲面渲染
由于服装几何细节的随机性,隐式曲面绘制具有挑战性。在2D图像生成任务中,GANs在学习高保真局部纹理方面取得了令人印象深刻的成果。团队建议使用对抗性损失来学习更好的几何细节。为了实现这一目标,他们使用隐式渲染器增强了正向蒙皮模块,以在posedspace中的3D点2D投影和canonicalspace中的相应3D点之间建立直接对应关系,从而实现端到端训练。
给定2D姿势法线贴图中的一个像素p,其在deformed3Dsapcex’中的对应关系可由穿过p的光线与正向蒙皮曲面之间的交点确定:

其中rd和rc表示光线方向和原点,t表示沿光线的标量距离。然后,通过使用Secant函数沿光线找到占有率O’的第一个变化来确定交点x’。
研究人员同时通过正向蒙皮得到了p的canonical对应点x。求解每个像素的三维canonical对应关系,得到二维法线贴图:
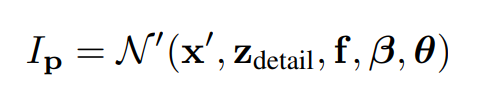
5.推断
团队通过从估计的高斯分布中随机抽样Zshape和Zdetail来生成人类化身。然后,使用MISE从隐式表示Sˆ(zshape,β)中提取调整resizedcanonicalspace中的网格,并使用法线field预测顶点法线。最后,按照公式(8)将网格设置为所需的姿势θ。
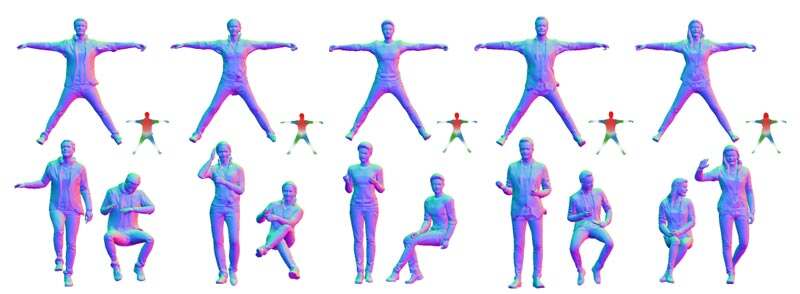
6.实验与总结

如上表所示,图案都的方法取得了相当出色的效果。实验显示,gDNA的表现明显优于基线。另外,gDNA可以用于3D扫描的拟合和重动画,并且优于最新技术SOTA。
概括来说,团队提出的3D穿衣人体生成模型gDNA可以生成大量具有详细皱纹和明确姿势控制的穿衣人体。使用隐式multi-subject正向蒙皮,只需根据每个subject的几个姿势扫描进行学习。为了模拟服装的随机细节,研究人员利用2D对抗损失来更新3D法线field。在实验中,他们证明了gDNA可以用于各种应用,如动画和3D拟合,并且效果优于最先进的方法。
当然,团队承认由于拓扑模糊性和pose-dependent非线性服装变形,从变形观测中学习宽松服装(如裙子)依然具有挑战性。
gDNA:TowardsGenerativeDetailedNeuralAvatars
总之,论文的主要贡献是:
原文链接:https://news.nweon.com/96560
来源媒体:YiVian







