





查看
与原始NeRF相比,所述方法将运行时间性能提高了1万倍,同时保持高质量的渲染效果
(
神经辐射场NeRF近来已经取得了重大进展,它能够生成逼真的新视角,并对view-dependent效果进行建模,如镜面反射。特别是,辐射场是一个由MLPs参数化的体三维函数,它可以估计在给定方向采样的三维位置的密度和发射的辐射度。然后,微分体三五i渲染允许通过最小化真实观察到的颜色和渲染的颜色之间的光度差异来优化这个函数。
尽管NeRF及其各种扩展的成功和巨大潜力前景,但一个不可回避的问题是渲染新视图的高计算成本。例如,即便是采用强大的现代GPU,NeRF渲染一张800×800像素的图像都需要30秒左右,这使得它无法用于AR/VR等交互式应用。
渲染NeRF表示的巨大计算成本主要来自两个方面:一是,对于每个单独的像素,NeRF需要沿着相应的射线采样数百个位置,查询密度,然后使用体三维渲染累积辐射度;二是,为了表示复杂场景的几何细节,需要大的模型尺寸,所以NeRF架构中使用的MLPs相对较深和宽,这为每个点样本的评估带来了大量计算。
在名为《LearningNeuralDuplexRadianceFieldsforReal-TimeViewSynthesis》的论文中,香港城市大学和Meta提出了一种可以实现高保真实时视图合成的方法。
为了避免沿每条射线的密集采样,一个解决方案是通过预训练的NeRF模型生成一个几何代理。通过利用高度优化的图形管道,团队几乎可以立即获得每条射线的采样位置。但由于表面周围的密度场不准确,提取的网格可能不能忠实地代表真实的底层几何,并可能包含伪影,如图2所示。

密集的局部采样可以在一定程度上缓解错误,但不能处理缺失的几何体或遮挡物。另一种方法是使用栅格化进行快速的神经渲染,直接将神经特征烘烤到表面。这通常伴随着一个深度CNN来将栅格化的特征转化为颜色,并学习解决现有的错误。这对评估而言成本昂贵,而且会阻碍实时渲染。
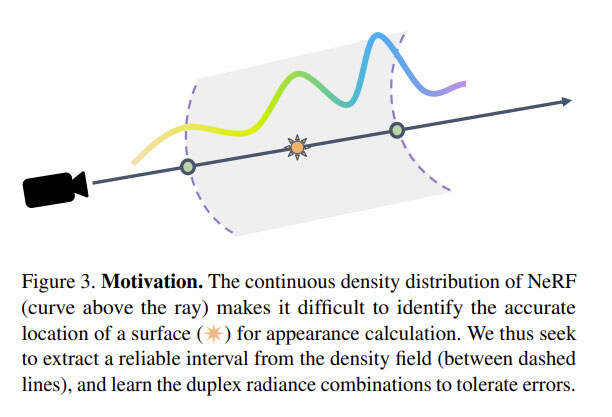
为了大幅减少采样数量,同时有效地处理几何错误,研究人员的第一个关键技术创新是根据沿射线的双联点的辐射度来推断最终的RGB颜色。如图3所示,NeRF表示沿每条射线的连续密度分布。尽管一般情况下很难确定沿射线的表面的确切位置,但通过使用对几何形状的underestimation和overestimation,将更容易提取对最终预测贡献最大的可靠区间。
在这个想法的引导下,香港城市大学和Meta没有选择一个特定的位置进行外观计算,同时没有在这个区间内进行昂贵的密集体三维渲染,而是在一条射线与二维几何体的两个交汇点上使用可学习的特征来表示场景,并使用神经网络从这个聚合的二维辐射度信息中学习颜色。
尽管只考虑了两个采样点,但团队发现,即便没有深度神经网络,这种神经双工辐射度场在补偿几何体代理的误差方面同样稳健,并且有效地保留了基于栅格化方法的效率。
NeRFMLP已经成为大多数神经隐含表征的最标准架构。但由于只考虑了沿射线的几个点,MLP很难约束所提出的神经双工辐射场。相反,团队使用了一个浅层卷积网络,它可以有效地捕获邻近像素的局部几何信息,并带来了相当好的渲染质量。
团队发现,直接从零开始训练神经双工辐射场会导致明显的伪影。所以,他们提出了一个多视图蒸馏优化策略,从而能够有效地接近原始NeRF模型的渲染质量。值得注意的是,与原始NeRF相比,所述方法将运行时间性能提高了1万倍,同时保持高质量的渲染效果。
方法
团队的主要目标是学习一种可以令高质量的、实时的、基于给定的NeRF模型的新视点合成成为可能的高效三维场景表征。为此,他们提出了神经双工辐射场(NeuralDuplexRadianceFields/NDRF)。这个新颖的概念可以将沿射线的采样点数量从数百个大幅减少到两个,同时很好地保留了复杂场景的现实细节。
尽管通过使用两层网格可以约束查询频率,但NeRF中基于每个样本的深度MLP的前向传递依然是一个负担,而且缺乏表现力,尤其是对于高分辨率的渲染场景。因此,研究人员提出了一种更有效的混合辐射度表示和着色机制。
为了进一步抑制潜在的伪影并提高渲染质量,他们利用多视图蒸馏信息来指导优化过程。最后,他们展示了完整的渲染过程和基于着色器的实现,从而实现实时的跨平台渲染。
我们先快速回顾一下NeRF的基本原理。简而言之,NeRF用一个可学习的MLP来近似计算5D全光函数,它将空间位置x∈R3和视图方向d∈S2映射为辐射度c∈R3和密度σ∈R。在从camera中心投出一条射线,通过一个像素进入场景后,其颜色是通过评估网络FΘ沿射线的多个位置进行计算,并使用体三维渲染来聚合辐射度。
影响NeRF渲染效率的一个关键因素是每条射线的3D采样位置的数量。由于NeRF的体三维表示法可以通过行进立方体转换为三角形网格,一个自然的想法是直接烘烤几何表面的外观,即只考虑射线-表面交叉点的辐射度。
然而,由于行进立方体的离散误差和NeRF固有的floaterartifact,生成的网格质量往往不够理想。基于光栅化的神经渲染方法使用深度CNN纠正屏幕空间的错误,但这不可避免地牺牲了渲染效率。由于几何代理已经传达了近似的三维结构,另一种方法是在表面周围进行局部采样。尽管这有助于应对低质量的网格,但它在处理缺失的几何体或可见的遮挡物时十分吃力,如图5所示。
Representation
值得注意的是,NeRF的密度分布决定了发射的辐射度对射线最终颜色的贡献,它可能包含多个峰值。这使得用单一的射线-表面交点来近似计算一个像素的颜色成为一个具有挑战性的主张。
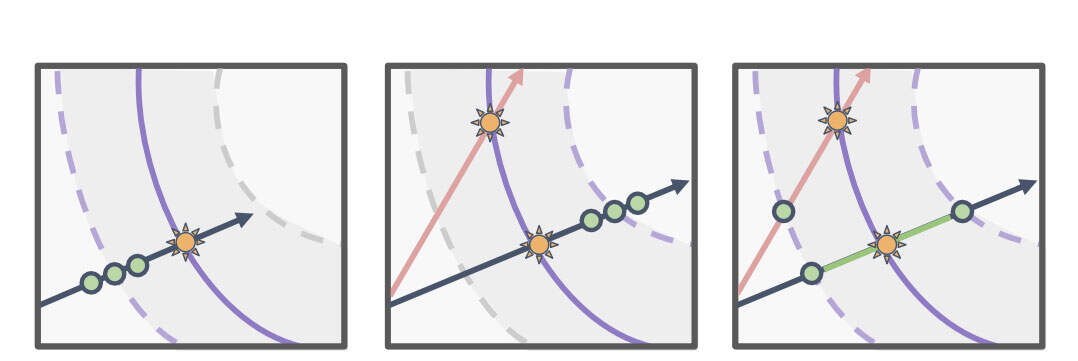
为了显著减少每个像素的采样点,同时保证渲染保真度,团队提出了神经双工辐射场FΘ∶R8×R3来表示光线,其中FΘ学习将由其两个端点x1和x2定义的光线段映射到集成的view-dependent颜色。
具体地说,目标是直接从密度分布的可靠区间定义的射线段中学习任何像素的颜色。研究人员将射线投射到两个代理网格表面,即inner的Mi(Vi,Ti)和outer的Mo(Vo,To),顶点位置为V●和三角形面为T●,从而获取射线段的端点。
所述网格是从NeRF的密度场的不同水平集中提取。更具体地说,射线颜色c可以通过以下公式计算:
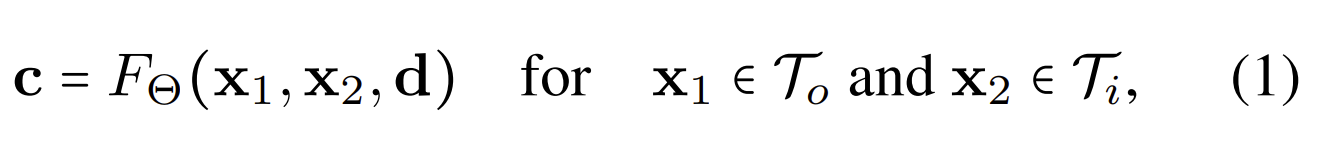
其中x1和x2是给定射线与Mi和Mo网格的深度排序相交,d表示视图方向。
考虑到不是所有的光线都会击中两个表面代理,团队依然附加了视图方向。然后,显式三角形网格将允许他们有效地获取光线表面相交,并受益于图形光栅化管道的完全并行性。在大多数隐式神经表示中,由于多层感知器的平滑性和紧凑性,不同的属性(如SDF、辐射或像素颜色)由多层感知器编码。然而,考虑到推理的高计算成本,密集地评估深度MLP并不是实时应用的明智选择。
由于辐射场是通过两个几何曲面定义,编码是通过直接将可学习的特征fk∈RN附加到每个网格顶点vk来定义。为了获得三角形上任意点x的特征f(x),团队通过硬件栅格化并使用质心坐标在三角形内插值特征。因此,渲染方程可以重写为
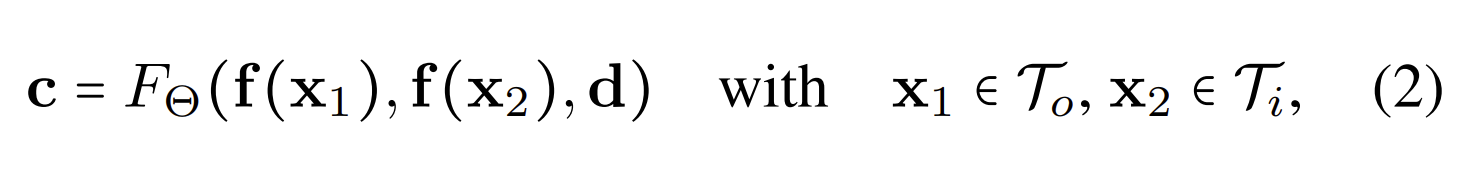
其中Θ参数化一个浅层网络来学习给定每条射线的辐射特征的聚合。
结果
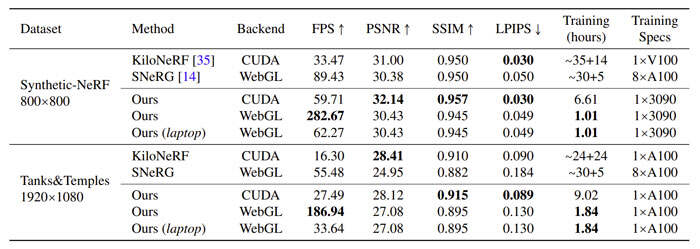
表1中提供了广泛的定量比较。与基于CUDA的KiloNeRF相比,团队的CUDA版本在PSNR(超过1dB)和SSIM方面取得了明显更好的渲染性能,运行时FPS更高,训练时间更短。

基于CUDA的模型在Tanks&Temples方面的PSNR略低于KiloNeRF,如图7所示。这可能是由于PSNR的特性导致,因为它只测量像素级的差异,而忽略了结构的相似性。在这种情况下,SSIM将是一个更好的指标来表示所述方法和KiloNeRF之间的性能差距(0.915vs.0.910)。
团队同时比较了基于webgl的SNeRG。即使在1920×1080分辨率下,他们基于webgl的模型都能在桌面级GPU实现180+FPS,并在使用笔记本电脑实现30+FPS,同时具有比SNeRG更好的渲染保真度。
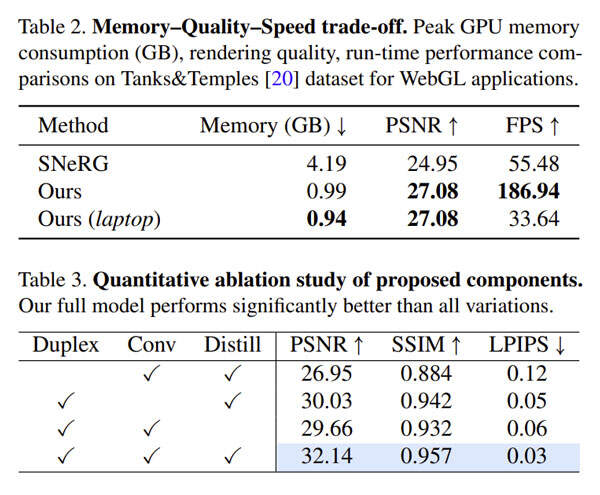
另外,与SNeRG相比,所述方法需要的训练计算量减少了大约两个数量级。表2展示了高分辨率设置下内存消耗、图像质量和渲染速度的权衡比较,全面展示了团队方法的优越性。
为了进一步验证方法在渲染质量方面优于现有的快速渲染NeRF技术,图7中展示了定性比较。可以看到,基线KiloNeRF和SNeRG都不能渲染场景的高质量细节,这可能受到体素分辨率的限制。然而,单纯提高体素分辨率将直接导致内存成本的三次增长。另外,在基线中存在一定的纹理伪影和错误的view-dependent镜面高光,在视觉上不如团队的方法。相比之下,他们的方法可以呈现出一致性和高保真度的视图,并且具有良好的视图泛化能力。
为了验证神经双工辐射的有效性,研究人员将其与仅考虑单个射线表面相交的变化进行了比较。更具体地说,只采用阈值为10-4的NeRF模型提取的网格,以确保几何代理能够覆盖所有像素并避免孔洞伪影。

如表3和图8所示,由于从NeRF提取的粗糙几何结构无法提供合理的着色位置,因此没有双工辐射的渲染会大大降低新视图合成的质量。
与大多数NeRF方法只沿单一光线积分辐射不同,团队通过卷积核聚合局部几何表面的所有辐射信息。图8和表3表明,卷积着色网络可以更稳健地呈现高保真的新视图,并且在每条光线只考虑两个样本位置的情况下,有效地克服了约束不足的问题。
图8中的结果表明,没有蒸馏视图的优化将导致几何图形中的高频伪影,而空间卷积核同样无法有效地处理。
在表1中,降低辐射特征维度和网络大小会导致一定的质量退化。因此,一个有趣的问题是,是否可以通过增加网络参数和感受野来持续提高性能。他们在Fox数据集上进行了这个实验。更具体地说,将网络层增加一倍,并用更大的感受野增强原始使用的卷积层。如图9所示,更深的网络并没有带来更多的质量收益。相比之下,合成的新视图比团队提出的方法更加模糊,并且丢失了诸多纹理细节,这可能是由于深度网络的学习困难造成。

由于方法涉及多视图蒸馏,研究人员在表4中测量了模型与Teacher模型之间的定量差异。尽管PSNR和SSIM的数值结果略逊于Teacher模型,但由于神经双工辐射场具有更好的泛化能力,与人类感知更相关的感知度量LPIPS出人意料地获得了更好的性能。另一方面,Teacher模型TensoRF对于现实世界的交互应用速度有限。相比之下,团队的方法在保持相当的渲染质量的同时达到30+FPS。
值得注意的是,WebGL版本比原始NeRF模型的速度提高了10000倍。另外,团队的方法可以在几个小时内使用单个GPU转换预训练的NeRF。
LearningNeuralDuplexRadianceFieldsforReal-TimeViewSynthesis
总的来说,香港城市大学和Meta提出了一种从预训练的NeRF中学习神经双工辐射场的新方法,并可用于实时新视合成。他们采用卷积着色网络来提高渲染质量,并提出了一种多视图蒸馏策略来更好地优化。所述方法在运行时提供了显著的改进,改善或保持了渲染质量,同时,与现有的高效NeRF方法相比,计算成本要低得多。
当然,从NeRF中提取有用的双工网格来表示透明或半透明场景是一项挑战,团队提出的方法同样不例外。另外,几何代理的质量将直接影响神经表征的学习。同时,所述方法目前主要关注对象级和有界场景数据集,所以有效地渲染现实世界的无界场景是一个未来方向。最后,实验表明,足够的可学习参数对于获得更好的渲染保真度至关重要。因此,为了应对WebGL版本中的性能下降,未来的研究可以考虑提高片段着色器中较大CNN的运行效率,或者利用其他加速框架。







