





查看
手部模型的有效神经网络重照明
(
与人脸不同,手存在一系列的关节,单个关节的状态会影响所有子关节。所以,即便是单个人体都会出现极其多样化的形状变化。姿势的变化会极大地影响手的外观,产生皱纹、投射阴影,并在较远区域相互反射。渲染所述效果具有挑战性,因为很难获得照片真实感所需的足够精确的几何体和材质属性。
同时,要达到足够精确的路径跟踪需要耗费大量的计算成本。使用简化的几何和外观模型(如线性混合蒙皮和减少的材质模型)可以加快计算速度,但渲染逼真度会明显降低。到目前为止,具有全局照明效果的可动画手部的实时真实感渲染依然是一个有待解决的问题。
在名为《RelightableHands:EfficientNeuralRelightingofArticulatedHandModels》的研究论文中,Meta和卡内基梅隆大学的研究人员希望以图片真实感渲染能够在新颖照明环境中使用新颖姿势进行动画设置,并支持渲染双手交互的个性化手部模型。
所以,团队提出了用于实时渲染的参数化3D手部模型的第一个神经重照明框架。具体来说,他们构建了一个可重照明的手部模型,以再现动态手部运动的light-stagecapture。研究人员捕捉了时空复用照明模式下的表现,其中全开启照明是交错的,以追踪手部几何结构和姿势的当前状态。
他们使用两阶段teacher-student方法来学习一个可以泛化到捕捉系统之外的自然照明的模型。首先训练一个teacher模型,在给定点光源位置、视图方向和光源可见性的情况下推断辐射。由于所述模型直接学习输入光位置和输出辐射之间的映射,所以它可以在不需要路径跟踪的情况下准确对手部复杂反射率和散射进行建模。
为了在任意照明中渲染手部,研究人员通过使用光传输的线性将自然照明视为远点光源的组合。然后,将teacher模型的渲染图作为pseudogroundtruth,从而训练以目标环境地图为条件的高效student模型。
他们发现,用于人脸的student模型架构在应用于可重照明手部时会导致严重的过度拟合,难以再现照明和手部姿势之间的几何交互。因此,团队建议使用受物理启发的照明特征来计算空间对齐的照明信息,包括可见性、漫反射和镜面反射。
由于所述特征是基于几何结构,并且近似于光传输的第一次反弹,所以它们与完整的外观表现出很强的相关性,并提供了足够的条件信息来推断自然照明下的精确辐射。特别是,可见性在解开光线和姿势方面发挥着关键作用,减少了对有限训练数据中可能存在的虚假相关性的学习。
然而,对于实时渲染来说,以全几何分辨率计算每一个光的可见性对计算而言过于昂贵。为了解决这个问题,团队建议使用与手部模型共享相同UV参数化的coarse代理网格来计算照明特征。
其中,计算coarse几何体顶点处的特征,并使用重心插值来创建纹理对齐的照明特征。全卷积架构学习补偿输入特征的近似性质,并推断局部和全局光传输效应。这样,模型可以在自然照明下以实时帧率渲染外观,如图1所示。

研究表明,整合可见性信息和空间对齐的照明特征对于泛化新的照明和姿势都非常重要。实验同时证明了所述方法支持实时渲染两只手,并在手上投射逼真的阴影。
1.1teacher模型
teacher模型AOLAT预测OLAT下的手部模型的外观:
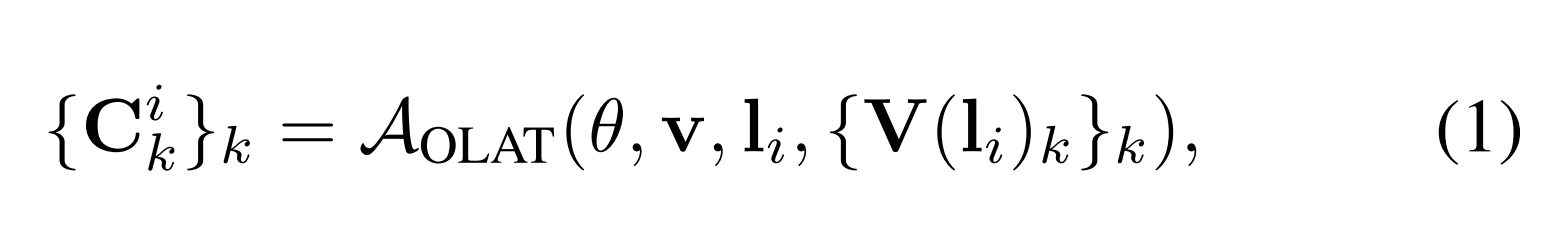
其中v是观看者的位置,li是第i个点光的位置,v(li)k∈Rs×s×s是使用深阴影贴图计算的从基元到光li的可见性贴图。
团队提出的部分照明框架使用L=5组照明来增加亮度和减少运动模糊,而不是OLAT。通过利用光传输的线性,这些光下的最终颜色{Cik}计算为每种光的基元颜色的加权和:

其中bi是每个光的强度,L是光的总数。与用于人脸重照明的teacher模型相比,团队在架构设计中进行了重要的修改,以支持使用混合网格体三维表示的手部重照明。
在人脸重照明中,以512×512的分辨率生成与视图相关的intrinsicfeaturemaps,并通过MLP和入射光方向进一步变换每纹理特征,以推断辐射度。
然而,基于MVP的解码器需要显著更大的信道尺寸来表示额外的体三维深度轴。因此,使用MLP对每个单个体素的辐射进行解码对计算而言不可处理。为了解决这一问题,研究人员采用了U-Net架构,以重塑的可见性贴图和空间对齐的照明和视图方向为输入。换句话说,对于每个基元k和光i,光方向编码为Fk,il∈R3×s×s×s,视图方向编码为Fkv∈R3×s×s×s。
将它们排列到UV空间中,以产生大小如下所示的体三维纹理贴图:

其中,w=64是UV贴图布局每侧的基元数,N=w×w是基元总数。图2展示了teacher模型的整体架构。

在人脸重照明中,尽管在以模型为中心的空间中计算了空间对齐的光方向,但这种全局参数化会导致关节对象的严重过度拟合,因为它忽略了关节产生的局部方向变化。为了解决这个问题,团队建议将视图和照明方向重定向为以图元为中心的坐标。
具体地说,每个基元k处的视图方向Fkv表示如下:
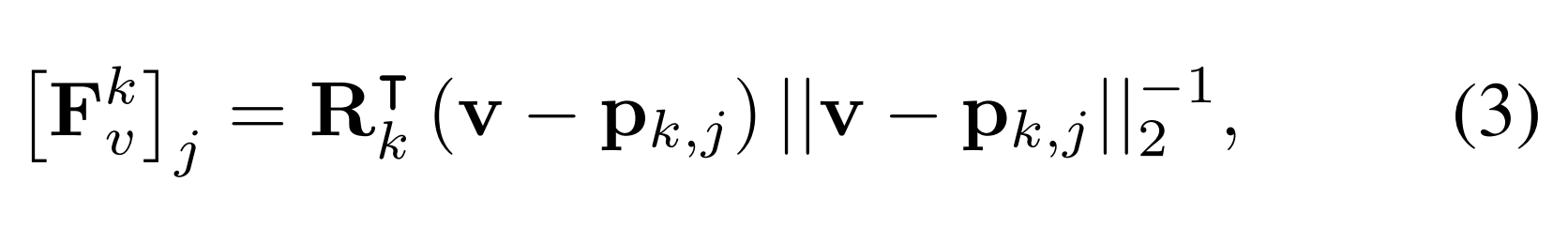
类似地,光方向Fk,il表示如下:
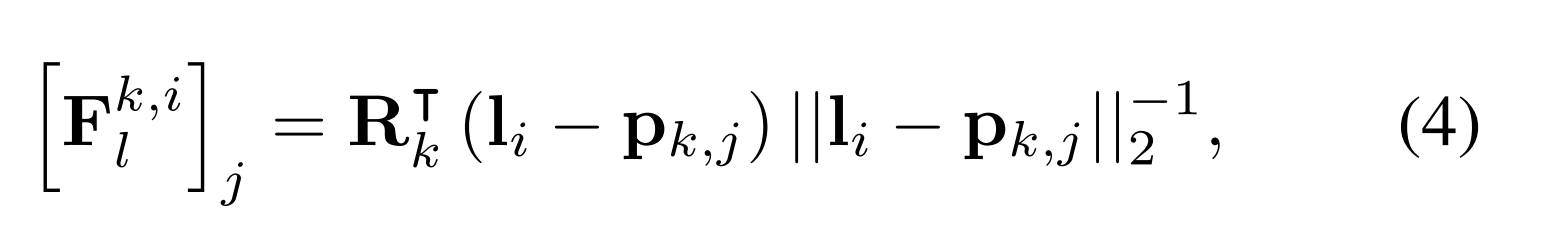
另外,关节特征是以U-Net层的最低分辨率级别输入,因此生成的外观显式说明了姿势相关的纹理变化,例如可能无法由基本体几何体表示的小褶皱。他们在UV空间中使用空间对齐的联合特征编码器。损失表示为:
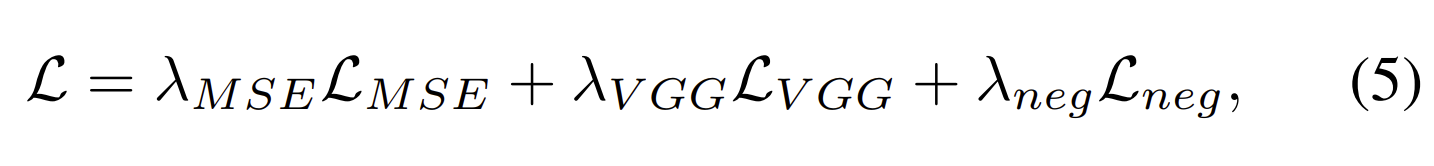
1.2student模型
student模型Aenv预测了手部模型在自然照明下的外观。student中的主要挑战是可以泛化到训练中不可见的照明和姿势的有效光编码。最先进的基于模型的人脸重照明方法引入了一种高效的超网架构,以16×32环境贴图的512维bottleneck表示为条件。研究人团发现,这种bottleneck照明表示很难泛化,因为它通过将其折叠成单个向量而失去了照明的空间几何形状。
这个问题对于可重照明手部来说更为明显,因为在这种bottleneck照明和姿势特征之间解开全局光传输不重要。
因为,团队参照社区发现提出了一种空间对齐的照明表示。其中,所述照明表示专为基于模型的手部重照明而定制,可以准确地解释由于姿势变化引起的自遮挡。换句话说,通过从每个顶点投射M条光线(每个envmap位置一条)来产生与纹素对齐的特征表示,并计算envmap值的加权和,以产生漫反射和镜面反射component。

他们通过将光线撞击其他网格部分的贡献设置为零来合并可见性信息。图4显示了可见性集成的效果。在实践中,使用coarse网格来计算每个顶点的特征,然后通过重心插值将特征投影到纹素对齐的空间。
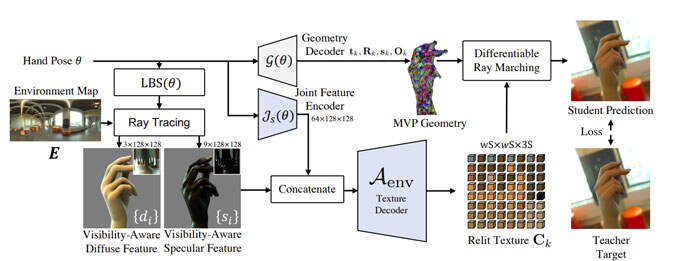
投影的特征馈送到全卷积解码器中,保持特征和输出外观{Ck}之间的空间对齐。图3展示了student模型的整体架构。
为了考虑手上空间变化的材质属性,研究人员采用具有多个光泽值(16、32、64)的镜面反射特征。特征贴图同时与空间对齐的联合特征连接。请注意,他们使用与teacher模型相同的损失来训练student模型。
为了训练teacher和student模型,团队使用Adam优化器,并将超参数λMSE、λVGG和λneg分别设置为1.0、1.0和0.01。他们在NVIDIAV100和A100上分别以0.001的学习率和4、2和4的批量大小对每个几何模块、teacher模型和student模型进行100000次迭代训练。另外,使用N=4096个基元,其每轴分辨率S为16。
为了减少训练数据在姿态方面的冗余,采用了基于内核密度估计的重要性采样,使用根归一化坐标中被跟踪的手部顶点的子集。他们用1000帧和25台摄像头生成25000张图像来训练student模型。
为了计算纹素对齐的照明特征,使用大小为M=512(16×32)的envmap,以及具有2825个顶点的coarse网格。同时,使用NVIDIAOptiX,通过GPU加速的三角形光线相交来计算可见性。
2.1teacher模型
他们首先使用lightstage拍摄的图像作为groundtruth来评估teacher模型的有效性。

根据在lightstage捕获的真实图像来评估由模型生成的图像的质量。如图5所示,teacher模型能够在多点光源下再现各种姿势依赖的外观,例如皱纹上的阴影以及皮肤和指甲上的反射。

表1显示,可见性输入显著提高了所有度量的准确性,尤其是对于双手序列。如图6所示,尽管没有可见性输入的模型可以通过依赖关节信息过度适应训练姿势,但它不能泛化到看不见的姿势或双手情况。因此,可见性条件对于超越训练姿势和光分布进行泛化至关重要。
2.2student模型

表2显示,在不可见手势和照明设置下,团队的方法在所有指标上都获得了最佳的MSE和SSIM分数。由于没有自然光照下的真实图像,因此使用了teacher模型生成的测试图像进行评估。
为了证实方法的有效性,他们与最新的基于模型的重照明方法进行了比较,并对可见性感知和镜面特征进行了消融研究。
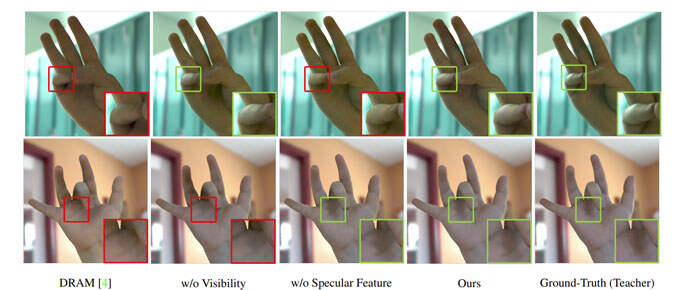
图7显示,与groundtruth相比,基于bottleneck的光编码无法匹配整体强度。另外,它缺乏细粒度的照明效果,如掠入射角的反射和柔和的阴影。相比之下,即使没有所提出的可见性集成,团队的空间对齐表示都显著提高了重建的保真度。
如表2所示,定量评估有力地支持了这一观察结果。另外,他们评估了所提出的计算特征的高效可见性集成的有效性。图7和表2显示,与没有可见性集成的模型相比,即使对于新颖的姿势和照明,完整模型都能实现更忠实的阴影重建。
团队同时验证了镜面反射特征在student模型中的重要性。尽管所述特征是在coarse代理几何体上计算,但图7和表2说明了镜面特征提供了足够的信息来再现镜面高光。这表明,空间对齐的照明特征对于实现可泛化的神经再照明至关重要。
研究的主要贡献之一是高效的渲染速度。尽管teacher模型通过聚集512(=16×32)个光源来生成带有envmap的纹理大约需要30秒,但student模型在NVIDIAV100上单手可达到48帧/秒(21毫秒),双手可达到31帧/帧(32毫秒)。
3.总结
总的来说,团队为关节式手部模型引入了第一个基于模型的神经重照明,以实现在各种照明下实时渲染个性化手部的真实感。他们成功地扩展了teacher-student框架,使用多视图lightstage捕捉数据的网格体三维混合表示来构建关节模型。
混合表示允许他们使用coarse网格来有效地计算受物理启发的光特征,并作为所提出的student模型的输入条件。实验表明,空间对齐的光表示和显式可见性集成对于高度可泛化的重照明至关重要。
当然,团队坦诚,由于远场光假设,student模型目前不支持其他附近物体的相互反射,但这可以通过将周围环境作为空间变化的环境贴图来部分解决。
未来的研究同时包括将所提出的方法扩展到穿衣身体,在这种情况下,在coarse网格处计算可见性不足以恢复由衣服变形引起的精细着色。另一个令人兴奋的方向是建立一个通用的可重照明点手部模型。







