





查看
适用于计算机视觉等用例
(
Theseus是一个为可微非线性优化提供跨应用框架的库。Theseus非常高效,可通过支持批处理、GPU加速、稀疏解算器和隐式微分来加速计算和内存。Meta宣称,它比
Theseus融合了将priorknowledge注入人工智能系统的两种主流方法的最佳方面。在深度学习出现之前,研究人员使用更简单、独立的AI优化算法来解决机器人中的单个问题。通过计算手动选择的因素组合的最小值,机器人系统学会了执行命令的最佳方式。这种方法有效但不灵活。特定于应用的优化算法通常难以适应新的系统或环境。
另一方面,深度学习方法的可扩展性要高得多,但它们需要大量的数据,会产生有效但在trainingdomain之外脆弱的解决方案。
为了训练特定应用的深度学习模型,研究人员使用精心选择的损失函数来衡量模型预测数据的效果。但要通过反向传播更新模型权重,每个层必须是可微分,允许误差信息通过网络流动。传统的优化算法不是端到端可微分,所以研究人员面临着一个权衡:他们可以放弃优化算法,转而进行专门针对特定任务的端到端深度学习,并有可能失去优化的效率及其泛化能力。
或者,他们可以离线训练深度学习模型,并在推理时将其添加到优化算法中。第二种方法的优势是将深度学习和priorknowledge相结合,但由于深度学习模型是在没有预存在信息或特定任务的错误函数的情况下训练,所以其预测可能不准确。
为了融合相关策略,减轻它们的弱点并利用它们的优势,Theseus将优化结果转换为一个可以插入任何神经网络架构的层。这样,修改可以通过优化层反向传播,从而允许研究人员对最终任务损失的特定domainknowledge进行微调,并作为端到端深度学习模型的一个组成环节。
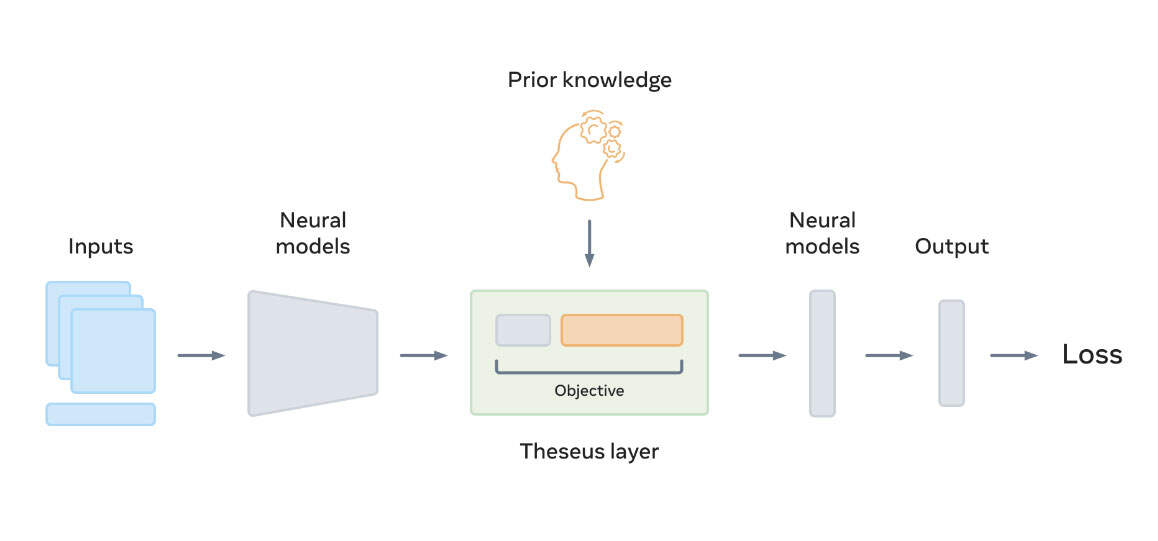
Theseus(绿色)如上所示,objective由上游神经模型的输出张量(灰色)和priorknowledge(橙色)组成。Theseus层的输出是最小化objective的张量。
这里。







