





查看
形成一种看似自拍,或者是由他人拍摄的图片感觉
(
在名为“Imagecapturinginextendedrealityenvironments”的专利申请中,
简单来说,用户可以“左手臂前伸,手指摆出V字胜利手势,并且露齿笑嘴角上扬”。这时,可以利用头显的朝外摄像头拍摄用户手臂前伸的手指V字姿势和现实世界场景,并通过头显的朝内摄像头拍摄用户的面容表情。然后,再通过机器学习模型整合成完整的姿势,并形成一种看似自拍,或者是由他人拍摄的图片感觉。
但需要注意的是,由于身体姿势必须前伸以置于朝外摄像头视场之内,并且由于头显的固有遮挡限制,朝内摄像头无法确切完整地捕获面容,叠加机器学习模型的性能问题,所以最终合成的图像无法精准表达用户的姿势表情。换句话说,这种方法存在自己的限制。

在一个实施例中,自我图像捕获系统可以包括自我图像启动引擎、Avatar引擎、背景帧引擎和合成引擎。自我图像帧可以对应于“自拍图片”或“自拍视频”。
自我图像启动引擎可以检测与自拍图片或自拍视频过程类似的用户输入,例如语音命令、手势输入以及其他类型的输入。基于检测到用户输入,自我图像捕获系统可以启动自图像捕获过程中的下一操作。
在一个示例中,Avatar引擎可以确定用户姿势。用户姿势可以包括和/或对应于用户的身体特征。例如,用户姿势可以包括用户当前的表情、情感、手势、肢体位置等中的一个或多个。另外,用户姿势可以包括和/或对应于用户在真实世界环境中的物理位置。Avatar引擎可以使用各种追踪和/或扫描技术和/或算法来确定用户姿势。例如,Avatar引擎3以使用一种或多种
接下来,Avatar引擎可以生成反映用户姿势的用户Avatar。需要注意,“Avatar”可以包括用户全部或部分的任何数字表示。在一个示例中,用户的Avatar可以包括计算机生成图像数据。可选地,用户的Avatar可以包括由图像传感器捕获的图像数据。另外,用户的Avatar可以对应于用户的抽象(例如卡通)表示或用户的照片真实表示。
在一个实施例中,Avatar引擎可以使用一个或多个机器学习系统和/或算法生成Avatar。例如,Avatar引擎可以基于使用机器学习算法对与各种用户姿势相关联的图像数据训练的机器学习模型来生成Avatar。例如,Avatar引擎可以捕获用户的一个或多个图像,例如用户的全身图像。基于捕捉到的用户姿势和用户的一个或多个图像,机器学习模型可以输出姿势与用户相似的Avatar。例如,如果捕捉到的用户姿势包括特定手势(例如“胜利手势”),则机器学习模型可以输出与做出特定手势的用户相似的Avatar。
在一个实施例中,背景帧引擎可以捕获一个或多个背景帧。背景帧可以包括和/或对应于将成为自我图像的背景的任何帧。
基于由Avatar引擎生成的Avatar和由背景帧生成的背景帧,合成引擎可以生成自我图像帧(或一系列自我图像帧)。例如,合成引擎可以将生成的Avatar叠加到背景帧。如上所述,Avatar引擎可以确定与用户姿势相对应的用户3D位置。因此,合成引擎可以将Avatar叠加在相应位置的背景帧内。通过这种方式,AR/VR头显就可以生成看似自拍或者看似由他人拍摄的图像感觉。
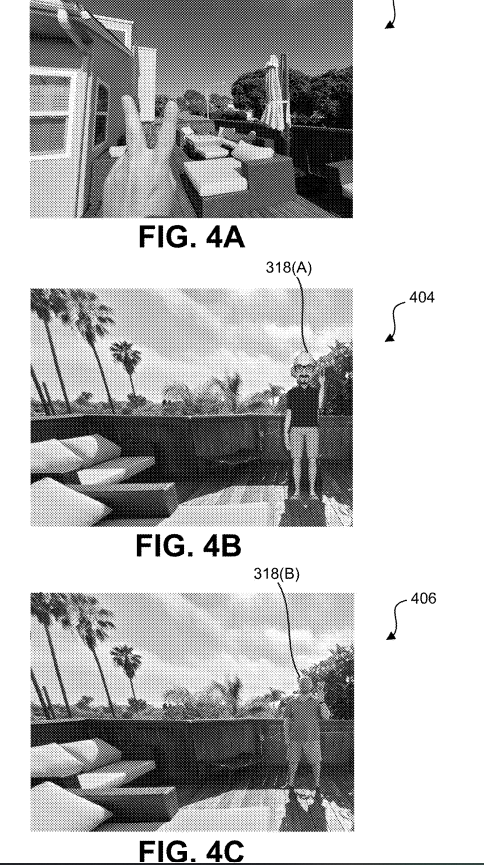
如图4A-4C所示。在图4A中,穿戴VR头显的用户可以前伸左手并摆出V字胜利手势。这时,系统可以通过头显的前置摄像头拍摄左手前伸并且手指摆出V字胜利手势的图像,以及周遭环境的背景图像。同时,系统可以确定头显用户在环境中的特定位置。
然后,Avatar引擎可以渲染Avatar318。同时,Avatar引擎304可以使用不同的机器学习模型来生成Avatar318(A)和318(B)。在一个示例中,Avatar引擎304(A)可以使用低保真度机器学习模型生成Avatar318(A),并使用高保真都模型生成Avatar318(B),如图4B和4C所示。换句话说,Avatar318(B)可以是Avatar318的高保真版本,一种更接近于图片真实感的版本。
然后,合成引擎308可以在生成自图像帧316时用Avatar318(A)或Avatar318(B)叠加到对应于用户在环境中的位置。
QualcommPatent|Imagecapturinginextendedrealityenvironments
名为“Imagecapturinginextendedrealityenvironments”的高通专利申请最初在2021年2月提交,并在日前由美国专利商标局公布。







